6.11. Проектирование баз данных
Проектирование баз данных
Проектирование баз данных — это системная инженерная дисциплина, направленная на создание структуры хранения данных, которая обеспечивает корректность, целостность, производительность, расширяемость и долгосрочную поддерживаемость информационной системы. Это архитектурное решение, влияющее на все слои программного обеспечения. Хотя Роберт Мартин, в своём подходе к архитектуре программного обеспечения, называет базу данных «деталью реализации», подчёркивая, что архитектура системы не должна зависеть от конкретного выбора СУБД, данное утверждение не умаляет значимости проектирования самой структуры данных. Вместо этого оно указывает на то, что логика приложения должна быть изолирована от особенностей хранения. Однако изоляция возможна только при условии грамотного проектирования: если структура данных изначально плохо организована, то абстракция не спасает — она лишь замаскирует растущие технические долги, которые рано или поздно приведут к деградации производительности, сложности сопровождения и даже невозможности реализовать новые функциональные требования.
Проектирование баз данных требует сочетания теоретической строгости (в том числе знания реляционной алгебры, теории нормализации, функциональных зависимостей) и практического опыта (умение предвидеть нагрузки, моделировать запросы, оценивать стоимость операций). Оно выполняется итеративно: каждый цикл должен опираться на чётко определённые принципы и проверяемые критерии. В рамках этой главы мы последовательно рассмотрим фундаментальные понятия, методологии, уровни абстракции, этапы жизненного цикла модели данных, а также особенности проектирования как реляционных, так и нереляционных систем.
Теория баз данных как основа проектирования
Перед тем как приступать к созданию схемы, необходимо понимать, что проектирование стоит на плечах строгой математической теории — теории реляционных баз данных, заложенной Эдгаром Коддом в 1970 году. Эта теория вводит понятия реляции, кортежа, домена, ключа, функциональной зависимости и транзитивного замыкания. Она формализует такие интуитивные идеи, как «уникальность», «связанность атрибутов», «избыточность» и «аномалии», переводя их в язык, пригодный для анализа и доказательства.
Центральным понятием является функциональная зависимость. Формально, атрибут B функционально зависит от атрибута A (записывается A → B), если каждому значению A соответствует ровно одно значение B. Например, в таблице сотрудников идентификатор сотрудника employee_id однозначно определяет его имя name и должность position:
employee_id → name,
employee_id → position.
Эта зависимость выражает причинно-следственную связь: зная ключ, мы можем однозначно восстановить остальные атрибуты кортежа. Важно понимать, что функциональная зависимость — это свойство моделируемой предметной области, а не артефакт реализации. Она существует независимо от того, как будет построена таблица.
На основе функциональных зависимостей формулируются фундаментальные свойства, лежащие в основе процедур нормализации:
-
Рефлексивность: Если Y ⊆ X, то X → Y. Любое множество атрибутов само себя определяет.
Например, из{id, name}функционально следует{id}. -
Пополнение (augmentation): Если X → Y, то X ∪ Z → Y ∪ Z. Добавление одинаковых атрибутов к обеим частям зависимости сохраняет её истинность.
Например, изid → nameследуетid, created_at → name, created_at. -
Транзитивность: Если X → Y и Y → Z, то X → Z.
Например, еслиuser_id → department_id, аdepartment_id → department_name, тоuser_id → department_name. -
Самоопределение (self-determination): Для любого множества атрибутов X, X → X. Это частный случай рефлексивности и обеспечивает, что каждая сущность может быть идентифицирована своим собственным набором ключей.
Эти правила позволяют вычислять замыкание множества атрибутов — то есть, все атрибуты, которые могут быть однозначно определены заданным набором. Замыкание лежит в основе алгоритмов поиска потенциальных ключей и проверки нормальных форм.
Другим важным понятием является декомпозиция — процесс разбиения отношения (таблицы) на несколько меньших отношений, которые в совокупности сохраняют всю исходную информацию без потерь. Декомпозиция считается без потерь (lossless), если естественное соединение (natural join) её результатов восстанавливает исходное отношение. Безпотерянность гарантируется, когда разбиение происходит по функциональной зависимости: если X → Y, то разбиение R на R₁(X ∪ Y) и R₂(R \ Y ∪ X) будет без потерь.
Обратным процессом является композиция — объединение нескольких отношений в одно. Композиция применяется, например, при денормализации, но требует осторожности, так как может привести к введению избыточности и аномалий.
Имеется также так называемая теорема о всеобщей зависимости (или теорема об универсальном объединении), утверждающая, что любое отношение можно без потерь разложить на бинарные отношения вида {A, B}, где A → B — элементарная функциональная зависимость. Эта теорема теоретически обосновывает возможность представления любой БД как набора двуместных связей (пар ключ–значение), однако на практике такое представление неэффективно, и компромисс достигается через нормальные формы.
Все эти понятия не являются абстрактной математикой — они используются при проектировании для выявления скрытых зависимостей, устранения избыточности и предотвращения аномалий обновления, вставки и удаления.
Например, аномалия обновления возникает, если одно и то же значение хранится в нескольких строках: при изменении необходимо обновить все копии, и пропуск хотя бы одной строки нарушает согласованность. Аномалия вставки — невозможность добавить сущность без наличия связанной сущности (например, нельзя добавить товар, если ещё нет категории). Аномалия удаления — потеря информации при удалении связанной записи (удаление последнего товара в категории ведёт к исчезновению самой категории). Нормализация — системный способ борьбы с такими аномалиями.
Уровни моделирования баз данных
Проектирование баз данных строится пошагово, через три последовательных уровня абстракции: концептуальный, логический и физический. Каждый уровень решает свои задачи, использует свой язык описания и адресован своей аудитории. Пропуск или смешение уровней — частая причина проектировочных ошибок.
Концептуальная модель
Концептуальная модель — это высокоуровневое, технологически независимое представление предметной области. Её цель — зафиксировать сущности, их атрибуты и связи между ними, не задумываясь о реализации в конкретной СУБД. Основным инструментом здесь является диаграмма «сущность–связь» (Entity-Relationship Diagram, ERD).
Сущность (Entity) — это класс объектов реального мира, обладающих общими свойствами и выделяемых в рамках задачи. Примеры: Пользователь, Заказ, Товар, Категория. Каждая сущность имеет уникальный идентификатор (обычно неявный на этом этапе) и набор атрибутов (name, email, price и т.д.).
Атрибуты могут быть:
- простыми (скалярными) — например, строка или число;
- составными — состоящими из податрибутов (например,
address* = {city, street, house}); - многозначными — допускающими несколько значений (например, phone_numbers).
Связи (Relationships) описывают взаимодействия между сущностями. Они характеризуются кратностью (cardinality) — количеством экземпляров одной сущности, которые могут быть связаны с экземпляром другой. Выделяют три основных типа:
-
Однозначная связь (One-to-One, 1:1) — каждый экземпляр сущности A связан не более чем с одним экземпляром сущности B, и наоборот.
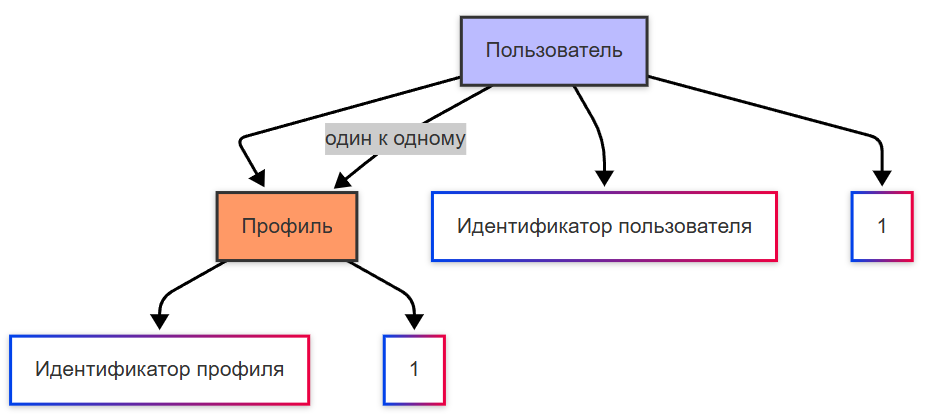
Пример: Пользователь ↔ Профиль. Физически такая связь может быть реализована либо объединением атрибутов в одну таблицу, либо двумя таблицами, связанными внешним ключом с уникальным ограничением. -
Связь «один ко многим» (One-to-Many, 1:N) — один экземпляр сущности A связан с нулем или более экземплярами сущности B, но каждый экземпляр B связан не более чем с одним экземпляром A.
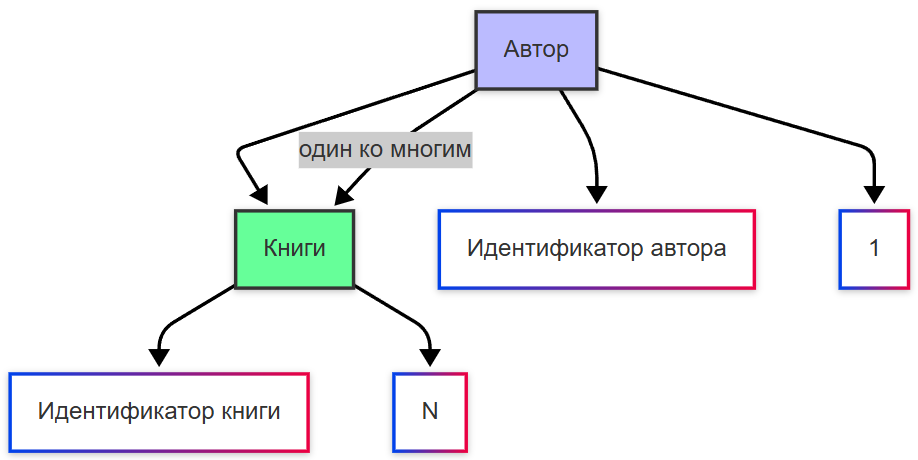
Пример: Категория → Товары. Эта связь реализуется в реляционной модели добавлением внешнего ключа в таблицу Товары, ссылающегося на первичный ключ Категории. -
Связь «многие ко многим» (Many-to-Many, M:N) — экземпляры обеих сущностей могут быть связаны друг с другом в произвольном количестве.
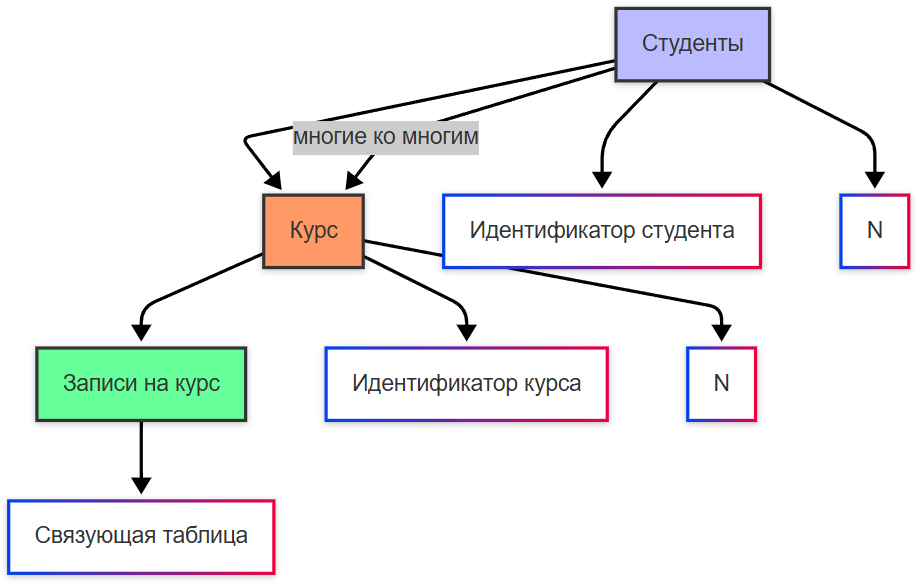
Пример: Студент ↔ Курс. Прямая реализация такой связи в реляционной модели невозможна; она требует введения связующей (ассоциативной) сущности — Запись на курс, которая сама становится сущностью с собственными атрибутами (например, дата зачисления, статус).
Помимо ERD, в промышленной практике, особенно в России и странах СНГ, широко применяется методология IDEF1X (Integration Definition for Information Modeling). Она более строга и формальна, чем классическая ER-модель, и разработана для поддержки проектирования в условиях высоких требований к целостности и документации (например, в оборонных или государственных проектах). IDEF1X вводит чёткое различие между:
- независимыми сущностями (strong entities) — идентифицируемыми собственным ключом;
- зависимыми сущностями (weak entities) — идентифицируемыми только в контексте другой сущности (например, Пункт заказа существует только в рамках Заказа);
- идентифицирующими и неидентифицирующими связями — в первом случае часть первичного ключа дочерней сущности заимствуется из родительской.
IDEF1X также строго регламентирует обозначения на диаграммах: прямоугольники для сущностей, ромбы — для связей, пунктирные и сплошные линии — для типов связей. Преимущество IDEF1X — в возможности автоматической генерации реляционной схемы и DDL-скриптов, а также в поддержке CASE-систем.
CASE-технологии и автоматизация моделирования
CASE (Computer-Aided Software Engineering) — это класс инструментов, поддерживающих полный жизненный цикл разработки информационных систем, включая проектирование баз данных. CASE-системы позволяют:
- визуально строить ERD или IDEF1X-диаграммы;
- проверять согласованность модели (например, отсутствие изолированных сущностей);
- генерировать логическую и физическую модели;
- синхронизировать изменения между уровнями;
- выпускать техническую документацию.
Современные аналоги CASE — это не столько отдельные тяжеловесные приложения (как ERwin или AllFusion), сколько облачные платформы (например, Vertabelo, DbSchema, Lucidchart с поддержкой ERD) и open-source решения (например, DrawSQL, dbdiagram.io). Они позволяют совместно работать над моделью, версионировать её, интегрировать с CI/CD и ORM-фреймворками.
Логическая модель
На этапе логического проектирования концептуальная модель транслируется в реляционную схему — формальное описание набора отношений (таблиц), их атрибутов (столбцов), типов данных, первичных и внешних ключей, а также ограничений целостности (constraints).
Каждая сущность ER-диаграммы превращается в таблицу. Атрибуты сущности становятся столбцами. Первичный ключ выбирается из минимального набора атрибутов, однозначно идентифицирующих строку. Внешние ключи реализуют связи:
- 1:1 — внешний ключ в одной из таблиц с
UNIQUE; - 1:N — внешний ключ в «многих»;
- M:N — отдельная таблица с двумя внешними ключами (и, обычно, собственным первичным ключом).
Одновременно с этим происходит выбор типов данных. Здесь важна не просто точность представления (например, DECIMAL(10,2) для денежных сумм вместо FLOAT), но и прогнозируемый объём роста:
- будет ли идентификатор укладываться в 32-битный
INT, или потребуется 64-битныйBIGINT? - нужен ли
VARCHAR(255)или достаточноVARCHAR(64)для логина? - требует ли поле поиска или сортировки — тогда тип должен поддерживать индексацию (не все типы
JSONиндексируются одинаково эффективно).
На этом этапе вводятся ограничения:
NOT NULL— запрет на отсутствие значения;UNIQUE— гарантия уникальности;CHECK— пользовательские правила (например,age >= 18);FOREIGN KEY— ссылочная целостность.
Важнейшим процессом логического проектирования является нормализация — пошаговое преобразование схемы к ряду нормальных форм, каждая из которых устраняет определённый класс аномалий и избыточности.
Процедура нормализации
Нормализация начинается с неформализованного отношения (например, таблицы, полученной напрямую из Excel или внешнего API) и проходит следующие стадии:
-
Первая нормальная форма (1НФ) требует, чтобы:
- каждый атрибут был атомарным (неделимым);
- не было повторяющихся групп (например, столбцов
phone1,phone2); - каждая строка имела уникальный идентификатор.
Нарушение 1НФ часто возникает при попытке «упаковать» список в один столбец (например, через запятую) или хранить JSON-массив в текстовом поле. Хотя современные СУБД поддерживают такие типы, их использование на уровне логической модели без веских причин — признак слабого проектирования.
-
Вторая нормальная форма (2НФ) накладывается на отношения, уже находящиеся в 1НФ, и требует, чтобы все неключевые атрибуты были полностью функционально зависимы от всего первичного ключа, а не от его части. Это актуально для составных ключей.
Пример: таблица ЗаказыТоваров(order_id, product_id, product_name, quantity). Здесь(order_id, product_id)— составной ключ, ноproduct_nameзависит только отproduct_id. Это нарушает 2НФ и ведёт к избыточности (название товара дублируется в каждом заказе). Решение — вынести товары в отдельную таблицу. -
Третья нормальная форма (3НФ) требует, чтобы неключевые атрибуты не зависели транзитивно от первичного ключа, то есть не зависели от других неключевых атрибутов.
Пример: Сотрудники(id, department_id, department_name). Здесьid → department_id, аdepartment_id → department_name, следовательно,id → department_nameтранзитивно. При изменении названия отдела придётся обновлять все записи сотрудников. Решение — вынести отделы в отдельную таблицу. -
Нормальная форма Бойса–Кодда (НФБК) усиливает 3НФ: каждая нетривиальная функциональная зависимость X → Y должна иметь X в качестве суперключа. НФБК устраняет оставшиеся редкие случаи аномалий, особенно при наличии нескольких кандидатных ключей.
-
Четвёртая (4НФ) и пятая (5НФ) нормальные формы решают проблемы, связанные с многозначными зависимостями и зависимостями соединения, но на практике применяются крайне редко — в основном в академических или узкоспециализированных системах.
Нормализация — средство. Её цель — обеспечить логическую целостность и минимизировать избыточность. Однако чрезмерная нормализация может привести к излишнему количеству JOIN-ов, что снижает производительность. Поэтому после достижения 3НФ или НФБК часто выполняется осознанная денормализация — возврат некоторых зависимостей с контролируемым дублированием данных, чтобы ускорить частые запросы.
Денормализация — это компромисс между целостностью и производительностью. Она оправдана, когда:
- запросы выполняются значительно чаще, чем обновления;
- данные редко меняются (например, справочники);
- критична скорость отклика (например, в аналитических системах OLAP);
- стоимость
JOIN-а неприемлема (например, в распределённых БД без эффективных distributed joins).
Денормализация должна быть документирована, обоснована метриками и, по возможности, поддерживаться автоматически (например, через триггеры или материализованные представления).
Этапы проектирования баз данных
Проектирование баз данных — это итеративная деятельность, в которой этапы могут перекрываться, возвращаться и уточняться в ходе разработки. Однако для системного подхода целесообразно выделить пять ключевых фаз, каждая из которых решает конкретные задачи и использует собственные методы и артефакты.
1. Анализ предметной области
Этот этап предшествует любому моделированию и заключается в глубоком понимании бизнес-контекста, целей системы и поведения пользователей. Результатом является глоссарий предметной области и перечень бизнес-сценариев.
Важно не ограничиваться формальными требованиями. Например, требование «пользователь может оформить заказ» кажется простым, но при детализации возникают вопросы:
- Может ли заказ включать товары из разных складов?
- Поддерживается ли частичная отгрузка?
- Есть ли статусы «в обработке», «отменён», «возврат»?
- Нужно ли хранить историю изменения статусов?
- Как обрабатываются возвраты денежных средств?
Ответы на такие вопросы напрямую влияют на структуру данных. Сущность Заказ может оказаться целым кластером: orders, order_items, order_status_history, order_payments, order_shipments.
На этом этапе также выделяются универсальные атрибуты, которые рекомендуется закладывать в каждую сущность с самого начала:
id— идентификатор (предпочтительно суррогатный);created_at,updated_at— временные метки;created_by,updated_by— ссылки на инициатора действия (внутренние пользователи, системы);is_deleted(илиdeleted_at) — для поддержки soft delete;description,notes— для неструктурированных пояснений.
Эти поля не несут прямой бизнес-ценности, но критически важны для аудита, отладки, восстановления и гибкости изменений. Их отсутствие в будущем может потребовать дорогостоящих миграций.
2. Концептуальное проектирование
На основе анализа строится ER-диаграмма (или IDEF1X-модель), отражающая сущности и связи. Здесь не используются термины «таблица», «столбец», «индекс» — только сущность, атрибут, связь, кратность.
Ключевые действия:
- Уточнение границ сущностей (например, Профиль — отдельная сущность или часть Пользователя?);
- Выявление скрытых сущностей (например, Адрес доставки может быть многократно используемым объектом);
- Определение кардинальности и обязательности связей («может ли заказ существовать без пользователя?»);
- Выявление обобщений и специализаций (иерархии «один ко многим»: Транзакция → Платёж, Возврат, Списание).
Диаграмма должна быть понятна разработчикам, аналитикам, заказчикам, предметным экспертам. Её обсуждение — эффективный способ выявить несоответствия на ранней стадии.
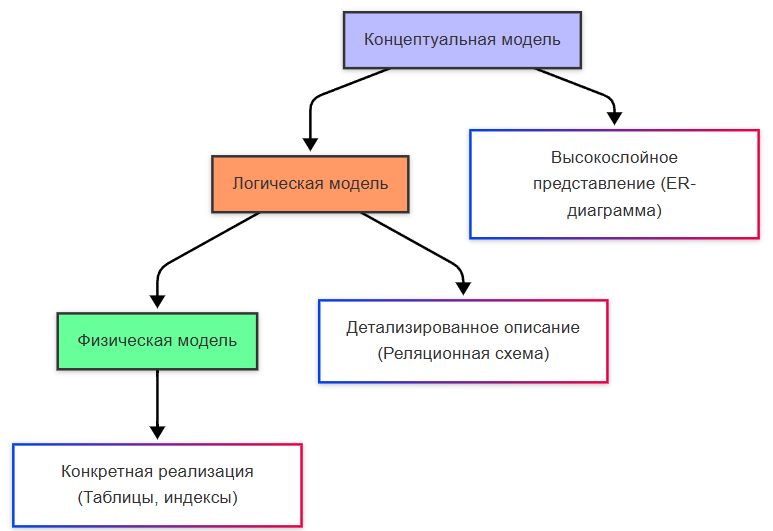
(Концептуальная модель — высокоуровневое, технологически независимое представление)
3. Логическое проектирование
Диаграмма транслируется в реляционную схему. Каждая сущность → таблица, связь → внешний ключ или ассоциативная таблица.
На этом этапе выполняются:
- Назначение типов данных с учётом диапазона, точности, локализации (например,
TIMESTAMPTZвместоTIMESTAMPпри работе с несколькими часовыми поясами); - Выбор первичных ключей — предпочтение отдаётся суррогатным ключам (
BIGINT,UUID), так как естественные ключи (например,email) могут меняться, быть неуникальными в будущем или содержать персональные данные; - Введение ограничений (
NOT NULL,UNIQUE,CHECK); - Применение нормализации до 3НФ или НФБК;
- Документирование зависимостей и бизнес-правил (например, «статус заказа может меняться только в порядке: new → paid → shipped → delivered»).
Результат — логическая схема, независимая от конкретной СУБД, но уже пригодная для генерации DDL.

(Логическая модель — детализированное описание данных с типами и связями)
4. Физическое проектирование
Логическая схема адаптируется под выбранную СУБД (PostgreSQL, MySQL, MS SQL и др.). Здесь принимаются решения, влияющие на производительность и управляемость:
- Выбор движка хранения (в MySQL: InnoDB vs MyISAM);
- Создание индексов:
- B-деревья для диапазонных запросов, сортировок,
WHEREиJOIN; - хэш-индексы — только для точного совпадения (ограниченно поддерживаются);
- частичные индексы (например, только для
is_active = true); - составные индексы с учётом порядка полей и правила «левого префикса».
- B-деревья для диапазонных запросов, сортировок,
- Партиционирование (фрагментация):
- горизонтальное — разбиение таблицы на подмножества строк по значению (например, по году
created_at, поuser_id % 16); - вертикальное — вынос редко используемых или больших полей (например,
full_description,metadata) в отдельные таблицы.
Партиционирование ускоряет запросы по диапазону, упрощает архивацию и позволяет локализовать блокировки.
- горизонтальное — разбиение таблицы на подмножества строк по значению (например, по году
- Настройка параметров хранения:
FILLFACTOR,TOAST(в PostgreSQL для больших объектов),compression. - Проектирование представлений (views) для упрощения сложных запросов и обеспечения стабильного API.
- Оценка необходимости хранимых процедур и триггеров (например, для ведения истории изменений или каскадных расчётов).
Физическая модель — это уже реализуемый артефакт: DDL-скрипты, миграции, конфигурации.
(Физическая модель — конкретная реализация в СУБД с индексами, партициями и т.д.)
5. Итеративное развитие и управление миграциями
База данных живёт дольше кода. Изменения неизбежны: новые требования, оптимизация, рефакторинг. Основной инструмент — миграции (migrations): версионированные, идемпотентные скрипты, изменяющие структуру БД.
Ключевые принципы:
- Миграции должны быть атомарными и обратимыми (или хотя бы иметь план отката);
- Каждая миграция — небольшое, проверенное изменение (не «переписать всю БД за раз»);
- Перед применением — полный бэкап и тестирование на копии;
- В продакшене — пошаговое применение с мониторингом блокировок и времени выполнения.
Для управления миграциями используются специализированные инструменты:
- Liquibase — XML/YAML/SQL-based, поддерживает сравнение схем, генерацию diff;
- Flyway — простота и скорость, основной формат — SQL-скрипты с нумерацией;
- Встроенные механизмы ORM (EF Core Migrations, Django Migrations, Alembic для SQLAlchemy).
Подходы, паттерны и антипаттерны
Помимо нормализации, в арсенале проектировщика — проверенные шаблоны, позволяющие решать типовые задачи. Их осознанное применение повышает качество системы.
Полезные паттерны
-
Surrogate Key
Использование искусственного идентификатора (обычноBIGINTс автоинкрементом илиUUID v4/v7) вместо естественного ключа (например,email,INN). Преимущества:- стабильность: идентификатор не меняется при изменении бизнес-атрибутов;
- производительность: целочисленные ключи короче и быстрее сравниваются;
- безопасность: не раскрывает бизнес-информацию (в отличие от, скажем,
order_number); - совместимость: одинаковое поведение во всех СУБД.
-
Soft Delete
Вместо физического удаления запись помечается как удалённая (is_deleted = true,deleted_at = NOW()). Это необходимо для:- аудита и восстановления;
- сохранения ссылочной целостности (например, нельзя удалить пользователя, если есть его заказы);
- аналитики (сколько пользователей когда-либо зарегистрировалось?).
Минусы — необходимость везде учитывать флаг, возможный рост таблицы. Компенсируется партиционированием «активных» и «удалённых» записей.
-
Temporal Tables / History Tracking
Хранение истории изменений в параллельной таблице (user_history) или с использованием системных возможностей (например,SYSTEM VERSIONINGв PostgreSQL 15+ или SQL Server). Позволяет отвечать на вопросы: «Как выглядел заказ 10 марта?», «Кто и когда изменил цену?». -
Materialized Path и Closure Table
Эффективные способы хранения иерархических данных (деревьев):- Materialized Path: хранение пути от корня (например,
/1/5/23/); поддерживает быстрые выборки поддерева, но требует обновления при перемещении узла. - Closure Table: отдельная таблица
(ancestor_id, descendant_id, depth), представляющая транзитивное замыкание дерева. Максимально гибка, но требует поддержания целостности.
- Materialized Path: хранение пути от корня (например,
-
Polymorphic Association
Ссылка на сущности разных типов (например, комментарий к посту, фото или видео). Реализуется через пару полей:target_type(ENUM или строка) иtarget_id. Альтернатива — отдельные связующие таблицы (post_comments,photo_comments), что строже, но менее гибко.
Антипаттерны
-
«Слишком много JOIN’ов»
Запросы, объединяющие 10+ таблиц, — признак чрезмерной нормализации или неудачной декомпозиции. Решение: денормализация критичных веток, материализованные представления, или перенос логики в приложение (если бизнес-правила сложны). -
«Гигантская таблица» (Entity-Attribute-Value, EAV)
Хранение атрибутов в виде строк:entity_id,attribute_name,attribute_value. Позволяет добавлять «поля» без изменения схемы, но убивает производительность, затрудняет типизацию и индексацию. Использовать только при крайней необходимости (например, медицинские показатели с сотнями редко используемых параметров). -
«JSON в столбцах» как замена нормализации
Современные СУБД отлично поддерживаютJSONB(PostgreSQL), но хранение структурированных данных (например, адрес как JSON) вместо отдельных столбцов city, street, house часто приводит к:- невозможности наложить
CHECK-ограничения на отдельные поля; - сложности с сортировкой и индексацией вложенных значений;
- увеличению размера записи (из-за JSON-синтаксиса).
Правило: если атрибут участвует вWHERE,ORDER BY,GROUP BY— выносите в отдельный столбец.
- невозможности наложить
Физические аспекты
Индексы
Индекс — это вспомогательная структура, позволяющая быстро находить строки по значению атрибута. В реляционных СУБД чаще всего используются B⁺-деревья, обеспечивающие логарифмическое время поиска и эффективную работу с диапазонами.
Правила проектирования индексов:
- Индексируйте все внешние ключи — это ускоряет
JOINи проверкуFOREIGN KEY; - Составные индексы строятся с учётом порядка: сначала поля в
WHERE, затем вORDER BY, затем вSELECT(последние — только если покрывающие); - Избегайте избыточных индексов (например,
(A, B)делает(A)частично избыточным); - Мониторьте использование через
pg_stat_user_indexes(PostgreSQL) илиsys.dm_db_index_usage_stats(SQL Server); - Помните: индексы замедляют
INSERT/UPDATE/DELETEи занимают место на диске.
Партиционирование
Партиционирование — стратегия управления жизненным циклом. Оно оправдано, когда:
- Таблица превышает размер оперативной памяти сервера;
- Часть данных устаревает и может быть архивирована или удалена (например, логи старше года);
- Нагрузка распределена неравномерно (например, 90% запросов — к последнему месяцу).
Типы:
- Диапазонное (
RANGE) — по дате, ID; - Списковое (
LIST) — по фиксированным значениям (регион, статус); - Хэш-партиционирование (
HASH) — для равномерного распределения.
Важно: запрос должен включать условие по ключу партиционирования, иначе СУБД выполнит сканирование всех партиций («partition scan»), что медленнее обычного full scan.
Кэширование
Кэширование — это компенсация стоимости запроса к БД. Оно применяется на разных уровнях:
- Уровень СУБД: кэш буферов (
shared_buffersв PostgreSQL), кэш планов запросов; - Прикладной уровень: кэш результатов (
Redis,Memcached) — для идемпотентных, редко меняющихся данных (справочники, профили); - Уровень запросов: материализованные представления или агрегатные таблицы, обновляемые по расписанию.
Ключевой вопрос: актуальность. Стратегии инвалидации:
- TTL (время жизни);
- событийная (
PUB/SUBпри изменении); - ленивая («если устарело — пересчитать при следующем запросе»).
Переход к NoSQL
Реляционная модель — не универсальное решение. При работе с большими объёмами полуструктурированных данных, высокой скоростью записи или сложными связями могут быть предпочтительны нереляционные (NoSQL) системы.
Основные модели NoSQL и их проектирование
-
Ключ–значение (Redis, DynamoDB)
Проектирование сводится к выбору ключа: он должен обеспечивать равномерное распределение и включать контекст, позволяющий избежать дополнительных запросов.
Пример:user:123:profile,session:abc456:cart.
Данные — простые структуры (строки, хэши, списки). Используется в основном для кэширования и сессий. -
Документные (MongoDB, Couchbase)
Документ — автономная единица данных (обычно в формате BSON/JSON). Проектирование идёт от запроса к данным:- Какие операции будут выполняться?
- Нужны ли агрегации?
- Как часто обновляются вложенные поля?
Основной приём — вложенность (embedding): хранение связанных данных в одном документе (
orderсодержит массивitems). Это устраняетJOIN-ы, но может привести к увеличению размера и конфликтам при частых обновлениях.
Альтернатива — ссылки (DBRefили простыеid), но тогда клиент должен выполнять дополнительные запросы. -
Колоночные (ClickHouse, Cassandra)
Данные хранятся по столбцам, а не по строкам. Это даёт колоссальный выигрыш при агрегации и аналитике:- только нужные столбцы читаются с диска;
- эффективное сжатие (значения в столбце однородны);
- векторизованные вычисления.
Проектирование требует продумывания primary key (в ClickHouse —
ORDER BY) как комбинации полей, по которым будут фильтроваться и группироваться данные. Например,(event_date, user_id, event_type). -
Графовые (Neo4j, Amazon Neptune)
Базируются на модели узлов (Node), связей (Relationship) и свойств (Property). Проектирование — это определение типов узлов и связей, а также направлений и атрибутов связей.
Запросы выполняются на языке Cypher (в Neo4j) с использованием шаблонов обхода:MATCH (u:User {id: 123})-[:FRIEND*1..3]-(friend)
RETURN friend.nameЭффективно для рекомендаций, мошенничества, сетевого анализа.
CAP-теорема и выбор конфигурации
В распределённых системах невозможно одновременно обеспечить:
- C (Consistency) — все узлы видят одни и те же данные в один момент времени;
- A (Availability) — каждый запрос получает ответ, даже при отказе узлов;
- P (Partition tolerance) — система продолжает работать при сетевом разделении.
Любая распределённая БД жертвует одним из трёх. Выбор зависит от требований:
- CA + P (PostgreSQL с синхронной репликацией): при разделении часть узлов отключается, но данные остаются согласованными.
- AP (Cassandra, DynamoDB): система остаётся доступной, но разные узлы могут временно возвращать разные версии данных.
- CP (ZooKeeper, etcd): при разделении доступность теряется, но данные всегда согласованы.
Проектирование под NoSQL требует отказа от привычных паттернов:
- Нет
JOIN— данные дублируются (денормализация); - Нет транзакций в глобальном масштабе (только в пределах шарда/партиции);
- Нет строгой схемы — но это не означает отсутствие соглашений;
→ вводятся схемы на уровне приложения, валидация в коде, документирование форматов.
Expand–Contract
Изменение структуры работающей системы — задача повышенной ответственности. Риск потери данных или простоя требует методичного подхода.
Метод Expand–Contract (также называемый «миграция без простоя»)
Это двухфазный процесс, минимизирующий риски:
-
Expand (расширение)
- Добавляется новая структура: столбец, таблица, индекс.
- Приложение модифицируется так, чтобы записывать данные в обе структуры (старую и новую).
- Чтение пока идёт из старой структуры.
- Выполняется миграция существующих данных (в фоне, с контролем скорости, чтобы не нагружать БД).
- Проверяется согласованность (например,
SELECT COUNT(*) FROM old WHERE NOT EXISTS (SELECT 1 FROM new WHERE ...)).
-
Contract (сжатие)
- Приложение переключается на чтение из новой структуры.
- После проверки стабильности запись в старую структуру прекращается.
- Старая структура удаляется (столбец
DROP COLUMN, таблицаDROP TABLE).
Пример: переход от VARCHAR name к разделённым first_name, last_name.
- Expand: добавляем
first_name,last_name; при сохранении парсимnameи пишем в оба места; фоновая миграция — разбор всех существующих записей. - Contract: переключаем UI на
first_name/last_name; через неделю удаляемname.
Преимущества:
- Возможность отката на любом этапе (просто откатить код и игнорировать новую структуру);
- Отсутствие downtime;
- Постепенный переход, без нагрузочных пиков.
«Пациента не спасти»
Когда нормализация и рефакторинг невозможны в обозримые сроки (миллионы строк, критичный uptime, отсутствие документации), применяются обходные стратегии:
- Read-through cache / Materialized views — для ускорения выборки строится параллельная оптимизированная структура, пополняемая через триггеры или CDC (Change Data Capture);
- Event sourcing — все изменения фиксируются как события; текущее состояние восстанавливается проекцией, что позволяет строить любые представления данных;
- Слоистая архитектура данных:
- Operational DB — legacy-система, только для записи;
- Analytics DB — отдельная, нормализованная или колоночная БД, в которую данные реплицируются по расписанию (ETL/ELT);
- Data Warehouse / Data Lake — для глубокой аналитики.
Такой подход позволяет «развязать» проблемы: разработчики работают с чистой схемой, а legacy остаётся в режиме «только запись» или «только поддержка».
Культура проектирования
Завершая главу, подчеркнём ключевой постулат: данные имеют большую долговечность и ценность, чем код. Приложения переписываются, языки устаревают, команды меняются — но данные остаются. Ошибка в проектировании БД может привести к:
- невозможности реализовать требование без полного перепроектирования;
- росту TCO (Total Cost of Ownership) на порядки;
- юридическим рискам (утеря, неаудируемость, нарушение GDPR/ФЗ-152).
Поэтому проектирование должно включать:
- Документирование: схема, обоснование решений, описание бизнес-ограничений, диаграммы потоков данных;
- Ревью: архитектурные советы, peer review миграций;
- Тестирование: нагрузочные тесты на реалистичных объёмах данных (не на 100 строках);
- Автоматизация: проверка схемы в CI (например, с помощью
sqlcheck,pgspot); - Ответственность: чёткое распределение ролей — кто проектирует, кто утверждает, кто применяет.
И да — иногда придётся отстаивать позицию перед заказчиком. Объясните «что будет, если сделать иначе»: «Если хранить все настройки в JSON, то через год поиск по региону будет занимать 15 секунд, и добавить индекс будет невозможно без остановки сервиса». Конкретика и аргументы — основа профессионального диалога.
Выбор СУБД
Решение о выборе системы управления базами данных принимается на этапе физического проектирования, но влияет на все последующие решения. Ошибочный выбор — одна из самых дорогостоящих архитектурных ошибок. Он приводит к:
- искусственным ограничениям на масштабируемость;
- избыточной сложности компенсационных механизмов;
- росту эксплуатационных издержек (лицензии, специалисты, поддержка).
Критерии выбора
-
Модель данных
- Реляционная (ACID, JOIN, транзакции) → PostgreSQL, MS SQL Server, Oracle, MySQL.
- Документная (гибкость, вложенность) → MongoDB, Couchbase.
- Колоночная (аналитика, агрегация) → ClickHouse, Apache Doris, Amazon Redshift.
- Графовая (связи, обходы) → Neo4j, Amazon Neptune.
- Ключ–значение (низкая задержка) → Redis, DynamoDB.
-
Согласованность и отказоустойчивость
- Требуется строгая согласованность (финансы, учёт) → PostgreSQL (с синхронной репликацией), MS SQL (Always On AG).
- Допустима eventual consistency (соцсети, IoT) → Cassandra, DynamoDB, ScyllaDB.
- Гарантированная доступность при сетевых сбоях → AP-системы (Cassandra, Riak).
-
Масштабируемость
- Вертикальное масштабирование (увеличение мощности сервера) — подходит большинству SQL-СУБД.
- Горизонтальное (добавление узлов):
- PostgreSQL — через Citus, TimescaleDB (для временных рядов), или шардинг в приложении;
- MongoDB — встроенный шардинг;
- Cassandra/DynamoDB — изначально построен на шардинге.
-
Экосистема и поддержка
- Наличие инструментов мониторинга (pg_stat_statements, MongoDB Atlas Metrics);
- Поддержка cloud-провайдеров (RDS, Cloud SQL, Azure DB);
- Наличие квалифицированных специалистов на рынке.
-
Ограничения лицензирования и стоимости
- PostgreSQL — open source, BSD-лицензия, коммерческая поддержка (EnterpriseDB, Crunchy Data);
- MySQL — open core, GPL + коммерческая лицензия для embedded;
- MS SQL Server — проприетарная, высокая стоимость лицензий и ПО;
- Oracle — дорогая enterprise-система, сложная лицензирование.
Рекомендация: не стремитесь к «единой БД для всего». Архитектура polyglot persistence — норма для сложных систем. Например:
- PostgreSQL — для транзакционных операций (заказы, пользователи);
- ClickHouse — для аналитики (отчёты, дашборды);
- Redis — для сессий и кэша;
- Elasticsearch — для полнотекстового поиска.
Проектирование в микросервисной архитектуре
Микросервисы вводят принцип bounded context (ограниченный контекст) — каждая служба владеет своей моделью и своей базой данных. Это радикально меняет подход к проектированию.
Антипаттерн: Shared Database
Использование одной физической БД несколькими сервисами — частая ошибка на ранних этапах. Последствия:
- Нарушение изоляции: изменение схемы одним сервисом ломает другой;
- Сложность развёртывания: миграции требуют синхронизации всех команд;
- Потеря автономности: сервисы связаны схемой.
Правильные подходы
-
Database per Service
Каждый микросервис имеет собственную схему или даже отдельную СУБД. Это максимизирует независимость.- Сервис Пользователи → БД
users; - Сервис Заказы → БД
orders; - Сервис Каталог → БД
catalog.
Связи между контекстами реализуются через:
- Синхронные API-вызовы (REST/gRPC) — просто, но создаёт жёсткую связь;
- Асинхронные события (Kafka, RabbitMQ, NATS) — через event sourcing или outbox pattern:
- При создании заказа сервис Заказы публикует событие
OrderCreated; - Сервис Аналитика подписывается и обновляет свою агрегированную таблицу.
- При создании заказа сервис Заказы публикует событие
- Сервис Пользователи → БД
-
Saga Pattern для распределённых транзакций
Когда операция затрагивает несколько сервисов (например, «оформить заказ + заблокировать средства»), используется saga — последовательность локальных транзакций с компенсирующими действиями.
Пример:ReserveInventory→ChargePayment→ShipOrder;- При ошибке
ChargePayment→CancelReservation.
Проектирование саг требует:
- Идемпотентности операций;
- Хранения состояния саги (в отдельной таблице или в потоке событий);
- Мониторинга «зависших» саг.
-
CQRS и Materialized Views
Разделение команд (запись) и запросов (чтение):- Операционная БД — нормализованная, для записи;
- Read-model — денормализованная, оптимизированная под конкретные UI-запросы (например,
user_profile_viewсname,email,last_order_date,total_spent).
Синхронизация — через события или CDC.
Безопасность на уровне схемы
Безопасность — не только «файрвол и пароли». Проектирование должно включать механизмы защиты данных на уровне СУБД.
1. Разграничение доступа (RBAC, ABAC)
- Роли, а не пользователи, получают права:
CREATE ROLE app_readonly;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO app_readonly; - Row-Level Security (RLS) — ограничение доступа к строкам на основе контекста:
Теперь даже при прямом SQL-доступе пользователь видит только свои заказы.
ALTER TABLE orders ENABLE ROW LEVEL SECURITY;
CREATE POLICY user_orders ON orders
USING (user_id = current_setting('app.user_id')::int);
2. Динамическое маскирование данных (Dynamic Data Masking)
Чувствительные поля (email, phone, passport) можно маскировать для непривилегированных ролей:
-- PostgreSQL 15+ (с помощью функций и RLS)
CREATE OR REPLACE FUNCTION mask_email(email TEXT)
RETURNS TEXT AS $$
SELECT regexp_replace(email, '.{1}(.*)@', '***\1@');
$$ LANGUAGE sql IMMUTABLE;
Или через встроенные средства (MS SQL, Oracle).
3. Аудит и журналы
- Включите
pgAudit(PostgreSQL) или SQL Server Audit; - Логируйте:
INSERT/UPDATE/DELETE, входы, DDL-команды; - Храните логи вне основной БД (в отдельной системе сбора).
4. Шифрование
- На уровне диска (LUKS, TDE) — защита от кражи носителя;
- На уровне приложения (AES-GCM) — для особо чувствительных полей (например,
encrypted_ssn).
Важно: не шифруйте поля, по которым нужен поиск или индексация.
Проектирование под нагрузки: OLTP, OLAP, HTAP
Требования к структуре кардинально различаются в зависимости от типа нагрузки.
| Критерий | OLTP (Online Transaction Processing) | OLAP (Online Analytical Processing) | HTAP (Hybrid) |
|---|---|---|---|
| Цель | Обработка транзакций | Анализ, отчёты | И то, и другое одновременно |
| Операции | Короткие, частые (INSERT, UPDATE) | Длинные, редкие (SELECT, агрегация) | Смешанные |
| Схема | Нормализованная (3НФ) | Денормализованная (звезда, снежинка) | Две схемы или columnar OLTP |
| Индексы | На FK, WHERE, сортировку | Мало индексов, bitmap | Адаптивные |
| Хранение | Row-oriented | Column-oriented | Columnar + delta-store |
| Примеры СУБД | PostgreSQL, MySQL | ClickHouse, Redshift, Snowflake | SingleStore, TiDB, HyPer |
OLTP: проектирование для скорости и целостности
- Минимизация
JOIN’ов в критичных путях (но без жертв 3НФ); - Использование
SERIALIZABLEилиREPEATABLE READдля критичных операций (например, перевод средств); - Оптимизация
UPDATE— избегайте обновления первичного ключа, меняйте только нужные столбцы.
OLAP: проектирование для объёма и скорости агрегации
- Схема «звезда»:
- Факт-таблица (например,
sales_fact) — миллионы строк, числовые метрики; - Измерения (например,
dim_date,dim_product) — нормализованные справочники.
- Факт-таблица (например,
- Использование материализованных представлений для предварительного расчёта агрегатов:
CREATE MATERIALIZED VIEW daily_sales AS
SELECT date, product_id, SUM(revenue)
FROM sales_fact
GROUP BY 1, 2; - Партитионирование по времени (
PARTITION BY RANGE (date)).
HTAP: компромисс с контролем
Современные СУБД (например, SingleStore, TiDB, ClickHouse с MergeTree + Buffer Engine) позволяют обрабатывать OLTP и OLAP-запросы в одной системе.
Ключевые приёмы:
- Разделение hot (активные) и cold (архивные) данных;
- Использование дельта-сторов (row-based) для записи и основного хранилища (columnar) для чтения;
- Автоматическая компактификация и миграция данных.
Работа с временными данными (Temporal Data)
Временные аспекты — когда данные были актуальны в реальном мире и когда они были зафиксированы в системе.
Два измерения времени:
- Valid Time (Business Time) — период, в течение которого факт истинен в предметной области.
Пример: сотрудник работал в отделе Разработка с2020-01-01по2023-12-31. - Transaction Time (System Time) — когда запись была сделана в БД.
Пример: запись о переводе создана2024-01-15 10:30.
Реализация
-
PostgreSQL 15+: встроенная поддержка через
PERIOD FORиSYSTEM VERSIONING:CREATE TABLE employees (
id BIGINT PRIMARY KEY,
name TEXT,
dept_id INT,
period FOR SYSTEM_TIME
);
ALTER TABLE employees ADD SYSTEM VERSIONING;Теперь можно запрашивать состояние на момент времени:
SELECT * FROM employees FOR SYSTEM_TIME AS OF '2023-06-01'; -
Вручную: добавление столбцов
valid_from,valid_to,created_at,updated_at,deleted_atи поддержание целостности через триггеры.
Польза:
- Ответ на вопрос «Что система знала 1 января?» (аудит);
- Ответ на вопрос «Какова была реальная ситуация 1 января?» (аналитика, отчётность);
- Восстановление после ошибок без полного бэкапа.
Документирование и аудит схемы
Хорошо спроектированная БД без документации — ловушка для будущих поколений разработчиков.
Что документировать:
- Схема данных — ERD/IDEF1X в актуальном состоянии (автогенерация из DDL);
- Глоссарий — пояснение каждого атрибута:
is_active: флаг,true= доступен для выбора в интерфейсе,false= скрыт, но не удалён;status: возможные значения —NEW,PAID,SHIPPED,CANCELLED; переходы — только в порядке возрастания.
- Бизнес-правила в схеме:
- «Цена товара не может быть ниже себестоимости» →
CHECK (price >= cost_price); - «Заказ без оплаты автоматически отменяется через 24 часа» — триггер или scheduled job.
- «Цена товара не может быть ниже себестоимости» →
- Миграции — каждая миграция должна содержать:
- Номер версии;
- Дату и автора;
- Описание изменения;
- Обоснование («Оптимизация запроса /orders/stats, который занимал >5 с»);
- Откат-скрипт.
Инструменты:
- DbVisualizer, DBeaver — экспорт ERD в PNG/SVG;
- Sphinx, MkDocs — генерация документации из комментариев в DDL:
COMMENT ON COLUMN orders.status IS 'Статус заказа: NEW, PAID, SHIPPED, CANCELLED'; - sqlc, Prisma — генерация типизированных клиентов из схемы, что само по себе является документацией.
Cистемный подход к проектированию
Проектирование баз данных — это дисциплина мышления, сочетающая:
- Теоретическую строгость (нормализация, функциональные зависимости);
- Практическую прагматичность (денормализация, кэширование);
- Стратегическое предвидение (масштабирование, эволюция, безопасность);
- Культурную ответственность (документирование, аудит, этика работы с данными).
Наиболее распространённые ошибки - методологические:
- Пренебрежение анализом предметной области;
- Смешение уровней моделирования (например, выбор СУБД до построения ERD);
- Оптимизация под текущий объём данных без прогноза роста;
- Отказ от документирования «потому что и так понятно».
Напомним: данные важнее кода. Хорошо спроектированная база данных:
- Позволяет быстро реализовывать новые требования;
- Снижает стоимость сопровождения на годы вперёд;
- Обеспечивает доверие со стороны бизнеса и регуляторов;
- Даёт инженерам спокойствие — знание, что фундамент надёжен.
Практическое приложение
1. Чек-лист проектировщика перед созданием таблицы
Перед тем как написать CREATE TABLE, задайте себе 15 ключевых вопросов. Ответы помогут избежать 90 % распространённых ошибок.
| № | Вопрос | Зачем? | Что делать, если ответ «нет» или «неизвестно» |
|---|---|---|---|
| 1 | Какая сущность предметной области отражается этой таблицей? | Избегаем «технических» таблиц без бизнес-смысла. | Вернуться к анализу требований. |
| 2 | Есть ли у сущности естественный ключ, стабильный и уникальный на годы вперёд? | Чтобы не создавать избыточный суррогат без причины. | Обычно — нет. Используем BIGINT или UUID. |
| 3 | Какие атрибуты являются обязательными (NOT NULL)? Какие — нет? | Предотвращаем «дырявые» записи, упрощаем логику приложения. | Продумать стратегию значений по умолчанию (например, status = 'DRAFT'). |
| 4 | Какие поля участвуют в WHERE, JOIN, ORDER BY, GROUP BY? | Основа для проектирования индексов. | Заранее спроектировать составные индексы, учитывая порядок. |
| 5 | Будет ли таблица расти быстрее, чем 1 млн строк в год? | Принять решение о партиционировании на ранней стадии. | Если да — продумать ключ партиционирования (дата, хэш ID). |
| 6 | Требуется ли хранить историю изменений? | Избежать болезненного рефакторинга «в бою». | Заложить created_at, updated_at, deleted_at; рассмотреть temporal tables. |
| 7 | Какие ограничения целостности нужны? (CHECK, UNIQUE, FOREIGN KEY) | Согласованность — гарантия СУБД. | Реализовать в DDL, а не в коде. |
| 8 | Может ли сущность быть удалена? Как — физически или логически? | Soft delete требует изменения всех запросов. | Если да — добавить is_deleted/deleted_at и включить в индексы. |
| 9 | Какие данные являются персональными или чувствительными? | Обеспечение соответствия GDPR/ФЗ‑152. | Продумать маскирование, шифрование, RLS. |
| 10 | Кто и как будет её использовать? (сервис, аналитик, админ) | Разные потребности — разные структуры (CQRS). | Возможно, нужен отдельный read-model. |
| 11 | Какие бизнес-правила жёстко связаны с данными? | Перенос логики в БД повышает надёжность и производительность. | Реализовать через триггеры, функции или CHECK. |
| 12 | Возможна ли параллельная запись (конкуренция за строку)? | Избежать аномалий сериализации. | Продумать уровни изоляции, optimistic/pessimistic locking. |
| 13 | Нужна ли поддержка нескольких языков/локалей? | i18n в данных — антипаттерн, если не спроектировано заранее. | Вынести локализуемые поля в отдельную таблицу entity_translations. |
| 14 | Какова максимальная длина текстовых полей? | Избежать TEXT везде — это дорого и неинформативно. | Оценить по реальным данным: VARCHAR(64) для логина, VARCHAR(255) для title, TEXT — только для описаний. |
| 15 | Как будет происходить эволюция схемы через 6–12 месяцев? | Поддержка Expand–Contract требует архитектурной закладки. | Избегать ALTER TABLE ... DROP COLUMN в продакшене; проектировать для миграций. |
Примечание: чек-лист не «формальность» — он фиксирует мыслительный процесс. Ответы можно сохранять в виде комментариев к миграции или в Confluence-странице.
2. Шаблоны DDL для типовых сценариев
Ниже — проверенные шаблоны на PostgreSQL (с пояснениями). Их можно адаптировать под другие СУБД.
2.1. Базовая таблица с аудитом и soft delete
CREATE TABLE products (
id BIGSERIAL PRIMARY KEY,
sku VARCHAR(32) NOT NULL UNIQUE,
name VARCHAR(255) NOT NULL,
description TEXT,
price NUMERIC(10,2) NOT NULL CHECK (price >= 0),
category_id BIGINT REFERENCES categories(id) ON DELETE SET NULL,
-- Аудит
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
updated_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
created_by BIGINT,
updated_by BIGINT,
-- Soft delete
deleted_at TIMESTAMPTZ
);
-- Автообновление updated_at
CREATE OR REPLACE FUNCTION set_updated_at()
RETURNS TRIGGER AS $$
BEGIN
NEW.updated_at = NOW();
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg_products_updated_at
BEFORE UPDATE ON products
FOR EACH ROW EXECUTE FUNCTION set_updated_at();
-- Индекс для активных записей (часто используется)
CREATE INDEX idx_products_active ON products (category_id)
WHERE deleted_at IS NULL;
-- RLS: только свои записи (для внутренних сервисов)
ALTER TABLE products ENABLE ROW LEVEL SECURITY;
CREATE POLICY user_products_policy ON products
USING (
created_by = NULLIF(current_setting('app.user_id', true), '')::BIGINT
OR current_setting('app.role', true) = 'admin'
);
2.2. Ассоциативная таблица для M:N с дополнительными атрибутами
-- Связь «пользователь — роль» с датой назначения и статусом
CREATE TABLE user_roles (
user_id BIGINT NOT NULL REFERENCES users(id) ON DELETE CASCADE,
role_id BIGINT NOT NULL REFERENCES roles(id) ON DELETE CASCADE,
assigned_at TIMESTAMPTZ NOT NULL DEFAULT NOW(),
assigned_by BIGINT,
status VARCHAR(16) NOT NULL DEFAULT 'ACTIVE'
CHECK (status IN ('ACTIVE', 'SUSPENDED', 'EXPIRED')),
PRIMARY KEY (user_id, role_id),
-- Уникальность активной роли на пользователя
UNIQUE (user_id, role_id, status)
INCLUDE (assigned_at)
WHERE status = 'ACTIVE'
);
-- Индекс для поиска ролей пользователя
CREATE INDEX idx_user_roles_user ON user_roles (user_id)
WHERE status = 'ACTIVE';
-- Индекс для аудита
CREATE INDEX idx_user_roles_assigned ON user_roles (assigned_at);
2.3. Таблица для временных рядов (event log)
CREATE TABLE user_events (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id BIGINT NOT NULL,
event_type VARCHAR(64) NOT NULL,
payload JSONB NOT NULL,
occurred_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
)
PARTITION BY RANGE (occurred_at);
-- Автоматическое создание партиций (через функцию или cron)
SELECT create_monthly_partition('user_events', '2025-01-01'::DATE, '2025-01-31'::DATE);
-- Частичный индекс для частых фильтров
CREATE INDEX idx_user_events_type ON user_events (event_type, user_id)
WHERE event_type IN ('LOGIN', 'PAYMENT', 'ORDER_CREATED');
-- Оптимизация для агрегаций
CREATE INDEX idx_user_events_ts ON user_events (occurred_at);
Замечание: партиционирование по времени — стандарт для логов, метрик, событий. Оно позволяет удалять старые данные через
DROP TABLE partition_2024_01, а неDELETE.
3. Типовые сценарии миграций (Expand–Contract в действии)
Сценарий 1. Переход от name к first_name/last_name
Цель: улучшить обработку имён (поиск, сортировка, формуляры).
| Этап | Действие | Риск | Митигация |
|---|---|---|---|
| 1. Expand | 1. Добавить first_name VARCHAR(64), last_name VARCHAR(64); 2. В коде: при сохранении парсить name и писать в новые поля; при чтении — использовать name; 3. Запустить фоновую миграцию: UPDATE users SET first_name = SPLIT_PART(name, ' ', 1), last_name = SPLIT_PART(name, ' ', 2) WHERE first_name IS NULL; | Блокировка таблицы при UPDATE | Использовать WHERE ctid BETWEEN ... AND ... или pg_cron с лимитом по 1000 строк/итерацию. |
| 2. Verify | Проверить согласованность: `SELECT COUNT(*) FROM users WHERE name != first_name | ' ' | |
| 3. Contract (read) | Переключить UI и API на first_name/last_name. Оставить запись в name для совместимости. | Ошибки в старых клиентах | Поддерживать обратную совместимость 1–2 релиза. |
| 4. Contract (write) | Прекратить запись в name. Установить CHECK (name IS NULL) на время. | Сторонние интеграции | Уведомить владельцев API. |
| 5. Cleanup | ALTER TABLE users DROP COLUMN name; | Невозможно откатить | Выполнять только после подтверждения стабильности. |
Сценарий 2. Добавление индекса на большую таблицу
Проблема: CREATE INDEX блокирует запись.
Решение: CREATE INDEX CONCURRENTLY (PostgreSQL):
-- Без блокировки DML (INSERT/UPDATE/DELETE продолжают работать)
CREATE INDEX CONCURRENTLY idx_orders_user_status
ON orders (user_id, status)
WHERE deleted_at IS NULL;
Важно: при ошибке индекс остаётся в состоянии
INVALID— нужно удалить и повторить.
4. Диагностика распространённых ошибок проектирования
Ниже — «симптомы», «диагноз» и «лечение» для 8 типовых проблем.
| Симптом | Возможная причина | Диагностика | Решение |
|---|---|---|---|
| Запросы замедляются пропорционально росту таблицы | Отсутствие индексов на WHERE/JOIN; full scan. | EXPLAIN ANALYZE; seq_scan в плане. | Добавить индексы. Проверить покрытие. |
| INSERT/UPDATE стали медленными | Слишком много индексов; триггеры; блокировки. | pg_stat_user_tables; n_tup_ins, n_tup_upd, n_idx_scan. | Удалить неиспользуемые индексы; оптимизировать триггеры. |
| Невозможно добавить запись без существования связанной | Неправильная кратность связи (например, 1:1 вместо 0:1). | Анализ требований: «может ли заказ быть без пользователя?» | Сделать FK NULL или добавить «гостевого» пользователя. |
| Одно и то же значение дублируется в сотнях строк | Нарушение 2НФ/3НФ. | Поиск повторяющихся значений (SELECT attr, COUNT(*) GROUP BY attr). | Декомпозиция: вынести в отдельную таблицу. |
| При обновлении цены все заказы «меняют прошлое» | Прямая связь вместо исторического снимка. | Проверка схемы: orders.price ссылается на products.price. | Хранить price в order_items на момент покупки. |
| Потеря данных при удалении родителя | ON DELETE CASCADE без учёта бизнес-логики. | Проверка DDL: REFERENCES ... ON DELETE CASCADE. | Заменить на ON DELETE SET NULL или RESTRICT; добавить soft delete. |
| Не получается выполнить миграцию — таблица заблокирована | Долгая транзакция или незавершённый ALTER. | SELECT * FROM pg_locks WHERE locktype = 'relation'; | Завершить блокирующие сессии; использовать CONCURRENTLY. |
| JSON-поле растёт, а поиск по нему медленный | Попытка заменить нормализацию на JSONB. | SELECT jsonb_pretty(payload) FROM ... LIMIT 1; — структура повторяется. | Вынести часто используемые атрибуты в отдельные столбцы; добавить GIN-индекс. |
5. Пример проектирования: интернет-магазин (итоговая сводка)
Рассмотрим, как применяются все принципы на практике.
Предметная область
- Пользователи, корзины, заказы, товары, категории, отзывы, скидки.
Этапы
-
ERD (концептуальная модель)
- Связи:
Пользователь1:1Корзина;Пользователь1:NЗаказ;Заказ1:NПозиция заказа;Позиция заказаN:1Товар;ТоварN:1Категория;Товар1:NОтзыв.
— общая схема; — детализация.
- Связи:
-
Логическая модель (3НФ)
users(id, email, ...),carts(id, user_id, ...),orders(id, user_id, status, ...),order_items(id, order_id, product_id, price_at_time, quantity, ...),products(id, sku, name, price, category_id, ...),categories(id, name, ...).
-
Физическая модель (PostgreSQL)
order_items.price_at_time— денормализация для сохранения цены на момент покупки;products.search_vector— для полнотекстового поиска (GIN-индекс);ordersпартиционирована поcreated_at;- RLS на
ordersдля доступа только к своим.
-
NoSQL-дополнения
Redis: сессии, корзины (временные);Elasticsearch: поиск по товарам.
-
Миграции
- Добавление
price_at_time— по сценарию Expand–Contract; - Введение партиционирования — через
pg_partman.
- Добавление
-
Безопасность
- RLS на
users.email; pgAuditдля всех DML;app.user_idиз JWT вSET LOCAL.
- RLS на