7.06. Контейнеризация
Контейнеризация
Контейнеризация, процесс развертывания с использованием контейнеров сейчас – важная часть разработки ПО.
★ Контейнер – «коробка», в которую упаковали приложение, со всеми нужными компонентами, чтобы просто можно было перенести эту «коробку» и запустить в другой среде. Только представьте, как это упрощает процесс доставки технологий между разными серверами.
Виртуальная машина
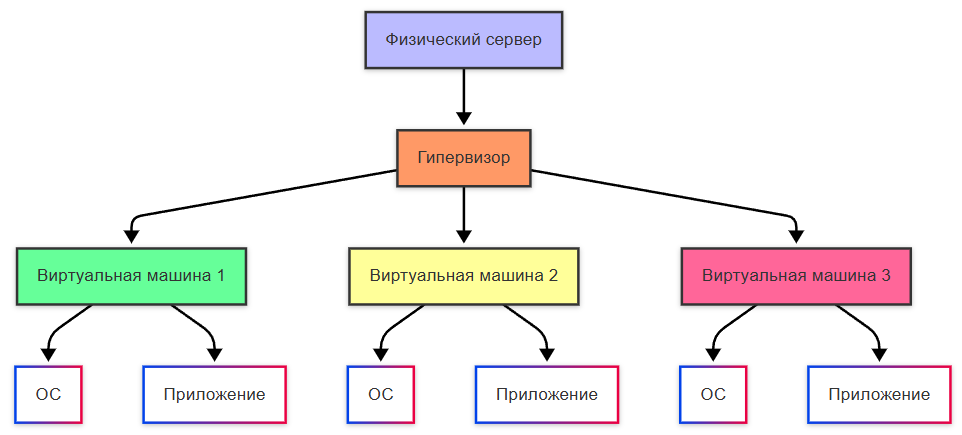
Контейнер

Это продвинутая часть разработки, но и технологии не стоят на месте. Изначально, приложения развёртывались на физических серверах (это традиционный подход, сейчас его тоже можно встретить), когда выделяется один сервер, на нем есть операционная система, набор ресурсов и среда для выполнения со всеми необходимыми компонентами. Но с ресурсами всегда беда – зависимость и дороговизна устройств, необходимость поддержки серверных. Тогда появился подход виртуальных машин, когда более крупные центры обработки данных закупались крупными мощностями и выделяли эти мощности в виде виртуальных машин (ВМ), когда на одном сервере можно было создать эти ВМ, распределять ресурсы между ними. Это подарило гибкость и устойчивость – ВМ проще восстановить, и ей легко добавить ресурсов, да и приложения становятся изолированными. И фактически, сервера стали кластерами ВМ.
Позднее, появились контейнеры – более лёгкие решения, которые тоже обладают своей файловой системой, процессором, памятью и компонентами, используя ресурсы ОС, но дают больше преимуществ:
- можно легко создать контейнер из образа;
- простой и быстрый откат образа контейнера;
- распределение задач во время сборки (то есть ДО развертывания на целевой инфраструктуре);
- наблюдаемость с информацией и метриками;
- независимость от платформ, переносимость, и идентичная окружающая среда, независимо – на ПК или в облаке;
- возможность разбивать микросервисы по приложениям, а не ВМ;
- большая компактность.
Контейнеры не требуют отдельной операционной системы для каждого экземпляра, в отличие от виртуальных машин, что снижает потребление ресурсов. Запуск и остановка контейнеров происходит быстро - на сервере установлена одна операционная система, которая используется всеми контейнерами.