Docker Swarm и Kubernetes
Docker Swarm и Kubernetes
Что такое кластеризация?
Мы разобрались, как работает контейнеризация. Но как быть, если контейнеров много, и речь идёт о масштабировании и обеспечении отказоустойчивости? Давайте разберём, что такое кластеризация, и как работают такие инструменты, как Docker Swarm и Kubernetes.
★ Кластеризация — это объединение нескольких серверов (или узлов) в единую систему для выполнения общей задачи. В контексте Docker кластеризация используется для следующих целей:
- Масштабирование - распределение нагрузки между несколькими узлами;
- Отказоустойчивость - если один узел выходит из строя, другие продолжают работу;
- Управление ресурсами - эффективное распределение ресурсов между контейнерами;
- Автоматизация - автоматическое развёртывание, мониторинг и восстановление контейнеров.
Кластеризация особенно важна, если контейнеров много, приложение должно быть доступно 24/7, и нужно масштабировать приложение в зависимости от нагрузки.
Кластеризация становится необходимой в следующих случаях:
- высокая нагрузка - если одно устройство не справляется с нагрузкой, нужно распределить её между несколькими серверами;
- отказоустойчивость - если один сервер выходит из строя, другие продолжают работу, минимизируя простои;
- географическое распределение - приложение обслуживает пользователей из разных регионов, и нужно разместить серверы ближе к пользователям;
- автоматизация - если нужно автоматически разворачивать, масштабировать и мониторить контейнеры;
- разделение ответственности - разные контейнеры могут работать на разных узлах, чтобы изолировать друг от друга.
Как работает кластеризация?
В кластере несколько серверов (узлов) объединяются в единую систему. Один из узлов обычно является менеджером (manager), который управляет остальными узлами (воркерами, workers). Менеджер отвечает за распределение контейнеров по узлам, мониторинг состояния узлов и восстановление контейнеров в случае сбоя.
Пример работы:
- у нас есть веб-сервер и много физических серверов;
- мы разворачиваем кластеризацию между физическими серверами - теперь это узлы;
- мы запускаем приложение (наш веб-сервер);
- менеджер определяет, на каком узле запустить контейнер;
- если нагрузка увеличивается, менеджер автоматически добавляет новые экземпляры контейнера на другие узлы;
- если один узел выходит из строя, менеджер переносит контейнеры на другие узлы.
Но опять же - не всё так просто.
Наше приложение, раз уж потребовалось масштабирование — это совокупность разного функционала. В приложении есть много аспектов - базы данных, кэширование, авторизация, каталог, сервисы, и многое другое. Мы уже затронули тему микросервисов ранее. Кластеризация касается именно этой темы.
Когда вы запускаете контейнер с базой данных (например, PostgreSQL), данные внутри контейнера хранятся в файловой системе контейнера. Однако, если контейнер удаляется или пересоздаётся, данные теряются.
Чтобы избежать этого, используются тома (volumes).
Тома — это специальные директории на хостовой системе, которые монтируются в контейнер. Данные сохраняются вне контейнера.
Пример:
docker run -d \
--name postgres \
-e POSTGRES_PASSWORD=mysecretpassword \
-v /data/postgres:/var/lib/postgresql/data \
postgres
Разбор:
docker run -dзапускает контейнер PostgreSQL в фоне на хосте или узле кластера.-e POSTGRES_PASSWORDзадаёт пароль суперпользователя при первом старте образа.-v /data/postgres:/var/lib/postgresql/dataмонтирует том: данные БД живут на диске хоста, а не в слое контейнера.- При пересоздании пода или контейнера на другом узле тот же путь тома сохраняет каталог данных.
- Имя
--name postgresупрощает ссылки вdocker logsи сетевых алиасах на одном хосте. - Для Swarm том обычно оформляют как named volume или распределённое хранилище, а не только hostPath.
- Образ
postgresбез тега подтянетlatest; в проде фиксируют версию (postgres:16-alpine). - Один контейнер — не кластер PostgreSQL: репликация и failover настраиваются отдельно (оператор, Patroni и т.п.).
Здесь /data/postgres — путь на хостовой системе, где будут храниться данные PostgreSQL. Если вы добавляете новый узел в кластер, данные остаются доступными через тома, независимо от того, на каком узле запущен контейнер.
Для отказоустойчивости и масштабирования базы данных используются реплики:
- Primary / replica : Один узел принимает записи, реплики обслуживают чтение (исторически говорили "master/slave").
- Распределенные базы данных : Например, PostgreSQL с шардированием или MongoDB с репликами.
Системы кэширования, например, Redis, хранят данные в оперативной памяти. При этом данные можно сохранять на диск для восстановления после перезапуска.
В кластере это работает так:
- одиночный Redis — один контейнер или под; при высокой нагрузке масштабируют репликами чтения или выносят в managed-сервис;
- Redis Cluster — несколько узлов и шардирование; для production настраивают отдельно (не одной командой
docker run).
Пример одиночного Redis с сохранением данных на том:
docker run -d \
--name redis \
-v /data/redis:/data \
redis:7-alpine
Разбор:
- Одноконтейнерный Redis подходит для кэша, сессий и учебных стендов без шардирования.
-v /data/redis:/dataсохраняет RDB/AOF на хосте, чтобы перезапуск не обнулял кэш и сессии.- Тег
7-alpineфиксирует мажорную версию и облегчённый образ;latestв проде избегают. - Память Redis по умолчанию эфемерна: том нужен, если включены
saveили AOF на диск. - Для высокой доступности один
docker runне заменяет Sentinel или Redis Cluster. - В Kubernetes тот же образ обычно описывают в Deployment/StatefulSet с PVC, а не
docker run. - Порт 6379 публикуется только при необходимости (
-p); внутри кластера достаточно Service. - Масштабирование чтения — реплики или managed Redis, а не копии одного standalone-контейнера.
Для Redis Cluster нужны минимум три мастер-узла (часто шесть с репликами), общая конфигурация и инициализация redis-cli --cluster create. В Kubernetes обычно используют оператор или Helm-чарт, а не один контейнер с --cluster-enabled.
redis-cli --cluster create
Разбор:
redis-cli --cluster createинициализирует топологию Redis Cluster после запуска нескольких узлов с--cluster-enabled.- Команде нужны IP:порт всех мастер-узлов; обычно указывают
--cluster-replicas 1для реплик на мастер. - Минимум для кворума — три мастера; типичный прод — шесть инстансов (3 master + 3 replica).
- Одной строки без аргументов недостаточно: в скрипте перечисляют узлы и подтверждают слоты.
- В Docker Swarm кластер Redis так почти не собирают; чаще — Helm-чарт или оператор в Kubernetes.
- После создания клиенты подключаются с флагом
-c(cluster mode) или через прокси. - Слоты (16384) распределяются между мастерами; перенос слотов —
redis-cli --cluster reshard. - Без постоянных томов и стабильных имён узлов пересборка контейнеров ломает привязку слотов.
Контейнеры в микросервисах
Касательно веб-приложений и микросервисной архитектуры, здесь стоит отметить следующее.
Микросервисная архитектура позволяет разделить приложение на независимые модули, которые могут быть запущены в отдельных контейнерах. Это упрощает масштабирование и управление.
Предположим, у нас есть веб-приложение, которое состоит из следующих компонентов:
- Авторизация: Микросервис для управления пользователями и аутентификацией.
- Каталог: Микросервис для управления товарами.
- Заказы: Микросервис для обработки заказов.
- Фронтенд: Контейнер с веб-интерфейсом.
- База данных: PostgreSQL.
- Кэширование: Redis.
В кластере это будет работать так:
- Авторизация и каталог могут быть размещены на одном физическом сервере.
- База данных и кэширование — на другом.
- Фронтенд и сервис заказов — на третьем.
Между собой микросервисы взаимоодействуют через API или сообщения (например, HTTP или gRPC). Для координации используются:
- Load Balancer : Распределяет запросы между экземплярами микросервисов.
- Service Discovery : Позволяет микросервисам находить друг друга (например, через DNS или Kubernetes).
Горизонтальное масштабирование. Если нагрузка на микросервис увеличивается, можно запустить дополнительные экземпляры контейнера.
Например:
docker service scale catalog-service=3
Разбор:
- Команда относится к Docker Swarm: меняет желаемое число задач (реплик) сервиса
catalog-service. - Swarm-менеджер распределяет новые контейнеры по worker-узлам с учётом ресурсов и constraints.
- Встроенная балансировка routing mesh направляет запросы на любой из трёх экземпляров сервиса.
- Имя сервиса должно существовать (
docker service createили stack); иначе команда завершится ошибкой. - Масштабирование вниз (
=1) аккуратно останавливает лишние задачи по политике сервиса. - Состояние приложения (сессии) при scale-out не переносится автоматически — нужен Redis или sticky sessions.
- В Kubernetes аналог —
kubectl scale deployment/...или полеreplicasв манифесте Deployment. - Изменение числа реплик не обновляет образ: для новой версии используют
docker service update.
Это создаст три экземпляра микросервиса "каталог".
Балансировка нагрузки. Load Balancer распределяет запросы между экземплярами микросервиса. Например:
- Nginx или Traefik могут использоваться для балансировки HTTP-запросов.
- Kubernetes автоматически управляет балансировкой через Service.
Отказоустойчивость. Если один экземпляр микросервиса выходит из строя, Load Balancer перенаправляет запросы на другие экземпляры.
Временные данные и сессии. Существуют и проблемы, например, проблема сессий. Если пользователь авторизован на одном экземпляре микросервиса, а его запрос перенаправляется на другой, сессия может быть потеряна. Решение - хранение сессий в Redis, чтобы они стали доступны всем экземплярам микросервиса.
Пример:
docker run -d \
--name session-store \
-v /data/redis:/data \
redis
Разбор:
- Контейнер
session-storeна Redis даёт общее хранилище сессий для всех реплик микросервиса. - Том
/data/redis:/dataсохраняет данные при рестарте контейнера на том же узле. - Без внешнего store при балансировке пользователь "теряет" сессию на другом экземпляре.
- В Swarm сервис лучше объявлять через
docker service createс overlay-сетью, а не одиночныйrun. - Пароль и ACL в примере не заданы — в проде включают
requirepassили Redis ACL через Secret. - В Kubernetes тот же паттерн — Deployment/StatefulSet Redis + Service и переменные подключения в ConfigMap.
- Версию образа (
redis:7-alpine) фиксируют, чтобы обновления не меняли поведение persistence. - Для отказоустойчивости одного контейнера недостаточно: нужны репликация или managed Redis.
Когда контейнеров становится много, требуется их оркестрация (своего рода дирижирование оркестром), то есть управление. Оркестраторы – это как раз те самые "дирижёры". Сейчас распространены Docker Swarm, Kubernetes и OpenShift.
Docker Swarm
Что такое Docker Swarm?
★ Docker Swarm — это встроенная система оркестрации Docker, которая позволяет создавать и управлять кластерами контейнеров. Она проста в использовании и интегрирована с Docker Engine.
Основные компоненты как раз - менеджеры и воркеры.
Менеджеры управляют кластером и отвечают за распределение задач и мониторинг, а воркеры выполняют задачи (запускают контейнеры).
Основные команды Docker Swarm
- Инициализация кластера:
docker swarm init
Разбор:
docker swarm initпереводит текущий Docker Engine в режим manager и создаёт однопользовательский Swarm-кластер.- В выводе появляются join-токены для worker и manager — их сохраняют для подключения других узлов.
- По умолчанию поднимается overlay-сеть
ingressдля routing mesh между сервисами. - Команда требует прав на сетевые порты (2377/tcp, 7946/tcp-udp, 4789/udp) на хосте.
- Повторный
initна том же узле ошибочен, пока узел уже в swarm (docker swarm leave --forceдля сброса). - Для HA нужно несколько manager-узлов (
docker swarm join-token manager). - Swarm встроен в Docker; отдельный control plane, как у Kubernetes, не устанавливается.
- После init сервисы создают через
docker service, а не толькоdocker runна менеджере.
Эта команда превращает текущий узел в менеджер.
- Добавление воркеров:
docker swarm join --token <token> <manager-ip>:<port>
Разбор:
- Worker (или дополнительный manager) подключается к существующему Swarm по токену и адресу менеджера.
<token>берут изdocker swarm join-token workerилиmanagerна узле-инициаторе.- Порт по умолчанию для gossip — 2377; в firewall должен быть открыт между узлами.
- После join узел получает задачи от scheduler Swarm и запускает контейнеры сервисов.
- Токены имеют срок действия; при утечке их ротируют (
docker swarm join-token --rotate). - Один хост — один swarm; повторный join без
leaveзавершится ошибкой. - Worker не участвует в raft-консенсусе менеджеров, но выполняет workload.
- Для вывода узла из кластера на worker:
docker swarm leave(на manager — осторожно с кворумом).
- Запуск сервиса:
docker service create --name my-service nginx
Разбор:
docker service createобъявляет сервис в Swarm: образ, имя и политики размещения задач.--name my-service— DNS-имя в overlay-сети для обращения между сервисами.- По умолчанию создаётся одна реплика; число задаётся флагом
--replicas. - Swarm тянет образ
nginxс registry (Docker Hub), если его нет локально на узлах. - Порты публикуют флагом
-p(published:target); без него сервис доступен только внутри overlay. - Обновления —
docker service update; откат — к предыдущей спецификации сервиса. - Сервис переживает падение контейнера: менеджер перезапустит задачу на доступном узле.
- Для стека из нескольких сервисов удобнее
docker stack deployс compose-файлом v3.
- Масштабирование:
docker service scale my-service=3
Разбор:
- Меняет целевое число одновременных задач (контейнеров) сервиса
my-serviceна три. - Swarm-scheduler создаёт или останавливает задачи без ручного
docker runна каждом узле. - Routing mesh распределяет входящие запросы между всеми здоровыми репликами сервиса.
- Можно масштабировать несколько сервисов в одной команде:
svc1=2 svc2=5. - Лимиты CPU/RAM задаются при
service create/update(--limit-cpu,--reserve-memory). - Масштаб не меняет тег образа; для релиза новой версии —
docker service update --image. - При нехватке ресурсов на worker-узлах задачи останутся в состоянии
pending. - В Kubernetes эквивалент — поле
spec.replicasDeployment илиkubectl scale.
Kubernetes
Что такое Kubernetes?
★ Kubernetes (k8s) - мощная платформа для оркестрации контейнеров, созданная Google и сейчас поддерживаемая сообществом CNCF.
Kubernetes сложнее Docker Swarm, но предлагает больше возможностей.
Официальный сайт - https://kubernetes.io/
Чит-лист - https://cheatsheets.zip/kubernetes
Kubernetes (K8s) – фреймворк для гибкой работы распределенных систем для масштабирования и обработки ошибок, предоставляя:
- мониторинг сервисов, балансировку нагрузки и распределение сетевого трафика;
- оркестрацию хранилища – автоматическое подключение дискового хранилища к контейнерам;
- автоматическое развертывание и откаты (можно автоматизировать для развертывания, удаления, распределения ресурсов в новый контейнер);
- самоконтроль – автоматический перезапуск отказавших контейнеров, замена и завершение работы;
- управление конфиденциальной информацией и конфигурацией (пароли, токены, ключи).
| Цель | Материал |
|---|---|
| Архитектура и инструменты | эта глава |
| Жизненный цикл Pod (от apply до удаления) | раздел ниже · справочник |
| Практика на Windows (Docker Desktop) | Первые шаги |
| Прод-подобный стек (Helm, HPA, Ingress) | Реализация Kubernetes |
| Справочник команд и YAML | Справочник по Kubernetes |
| Официальная документация kubernetes.io | Навигатор Kubernetes |
По официальному обзору Kubernetes — портативная расширяемая платформа с открытым исходным кодом для управления контейнеризованными рабочими нагрузками и сервисами. Название от греческого "рулевой"; проект открыт Google в 2014 году, сейчас развивается сообществом и CNCF.
Зачем оркестратор. В продакшене одного контейнера недостаточно — при сбое нужен перезапуск, при росте нагрузки — больше реплик, для сервисов — стабильный DNS и балансировка. Kubernetes автоматизирует это декларативно: вы задаёте желаемое состояние в манифестах, control plane выравнивает фактическое.
Что даёт платформа (по документации):
- обнаружение сервисов и балансировка нагрузки (DNS, Service);
- оркестрация хранилища (PV, PVC, StorageClass);
- автоматическое развёртывание и откат (Deployment, ReplicaSet);
- распределение подов по узлам по CPU/RAM (Scheduler);
- самовосстановление (перезапуск Pod, readiness/liveness);
- Secrets и ConfigMap без пересборки образа.
Чем Kubernetes не является: не PaaS "из коробки" (нет встроенной БД или CI/CD), не собирает исходный код, не заменяет мониторинг/логирование — только даёт механизмы интеграции. Это набор контроллеров, которые непрерывно сводят текущее состояние к желаемому.
★ Декларативная модель. Вы описываете в манифестах желаемое состояние (сколько реплик, какой образ, какие порты). Control plane сравнивает его с фактическим и запускает контроллеры, пока расхождения не исчезнут — reconcile loop. Вместо "запустить контейнер" — kubectl apply (см. блок команд ниже в примере Deployment/Service).
Упрощённый путь запроса: kubectl → API Server → запись в etcd → controllers (Deployment, ReplicaSet) создают/удаляют Pod'ы → Scheduler назначает Pod на Node → kubelet запускает контейнер через CRI.
Жизненный цикл Pod
Полный путь Pod — от kubectl apply до удаления и очистки ресурсов на узле. Ниже этапы в том порядке, в котором их видит кластер; подробная диагностика статусов — в справочнике Kubernetes, практика get/describe — в Первых шагах.
1. Приём манифеста и запись состояния
- Вы применяете манифест (
kubectl apply -f …) или контроллер создаёт Pod по шаблону Deployment. - kube-apiserver валидирует объект и сохраняет его в etcd — единственный источник правды о желаемом и фактическом состоянии кластера.
- В
metadataпоявляется запись Pod; полеstatusизначально пустое или частичное — его заполняют компоненты кластера по мере работы.
На этом этапе Pod уже существует как объект API, но контейнеры на узле ещё могут не запускаться.
2. Планирование (Scheduler)
kube-scheduler следит за Pod'ами без назначенного узла (spec.nodeName пуст). Он читает требования из spec (requests/limits CPU и памяти, affinity, tolerations к taints) и выбирает подходящий Node. Результат — привязка Pod к узлу; в Events появляется Scheduled.
Если подходящего узла нет, Pod остаётся в фазе Pending — типичный случай для диагностики через kubectl describe pod.
3. Запуск на узле (kubelet и Pod Sandbox)
На выбранном узле kubelet приводит Pod к описанному в манифесте состоянию через CRI (containerd, CRI-O):
- создаёт Pod Sandbox — изолированное окружение с общим сетевым namespace для всех контейнеров Pod;
- скачивает образы из registry (или использует локальный кэш);
- монтирует тома (PVC, ConfigMap, Secret, emptyDir);
- настраивает сеть (CNI назначает IP в pod network);
- запускает контейнеры в порядке, заданном манифестом (initContainers выполняются до основных).
Пока образ тянется или монтируется том, в kubectl get pods часто видят ContainerCreating или Init:0/1.
4. Фазы Pod (phase)
Колонка STATUS в kubectl get pods отражает фазу всего Pod (поле status.phase):
| Фаза | Смысл |
|---|---|
| Pending | Pod принят кластером; контейнеры ещё не запущены или узел не назначен |
| Running | Pod привязан к узлу; хотя бы один контейнер работает или перезапускается |
| Succeeded | Все контейнеры завершились с кодом 0 (типично для Job/CronJob) |
| Failed | Хотя бы один контейнер завершился с ошибкой |
| Unknown | kubelet на узле недоступен; состояние временно неизвестно API |
Отдельно смотрят conditions (PodScheduled, Initialized, ContainersReady, Ready) и READY n/m — сколько контейнеров прошли readiness probe. Под может быть Running, но 0/1, пока приложение прогревается.
5. Работа и перезапуски
Пока Pod в Running, kubelet следит за процессами — при падении контейнера срабатывает политика restartPolicy (Always, OnFailure, Never). livenessProbe перезапускает контейнер при сбое проверки; readinessProbe убирает Pod из endpoints Service, пока он не готов принимать трафик.
Счётчик RESTARTS в kubectl get pods растёт при каждом перезапуске контейнера внутри того же Pod.
6. Завершение и очистка
Удаление (kubectl delete pod …, масштабирование Deployment вниз, eviction) запускает graceful shutdown:
- Pod переводится в состояние Terminating (объект ещё в API, но с
deletionTimestamp). - kubelet отправляет контейнерам SIGTERM (аналог штатного
docker stop); время ожидания задаётterminationGracePeriodSeconds(по умолчанию 30 с). - По истечении grace period оставшиеся процессы получают SIGKILL.
- kubelet и CNI освобождают ресурсы — останавливают и удаляют контейнеры, отмонтируют тома, убирают сетевой интерфейс и IP Pod.
После этого запись Pod исчезает из etcd. Данные в PersistentVolume привязанного PVC сохраняются, если том не emptyDir.
На одной машине цикл короче: docker run → работа → docker stop (SIGTERM) → docker rm.
В Kubernetes те же идеи распределены между API Server, etcd, Scheduler, kubelet и CNI — см. жизненный цикл контейнера в Docker.
Официальное описание фаз и условий — Pod Lifecycle (EN).
API Kubernetes и объекты
Взаимодействие с кластером — через REST API (kube-apiserver). Состояние всех ресурсов хранится в etcd. Клиенты (в первую очередь kubectl) создают и изменяют объекты; каждый ресурс описывается полями apiVersion, kind, metadata, spec (желаемое) и status (фактическое, заполняет API).
- Версии API: alpha (
v1alpha1), beta (v1beta1), stable (v1). Устаревшие поля удаляются по deprecation policy. - Группы API: core (
/api/v1,apiVersion: v1) и именованные (/apis/batch/v1,apiVersion: batch/v1). - Спецификация OpenAPI доступна с apiserver:
GET /openapi/v2. - Расширение: CRD и API aggregation для собственных типов ресурсов.
Подробнее: API Kubernetes · Работа с объектами · навигатор.
Компоненты Kubernetes
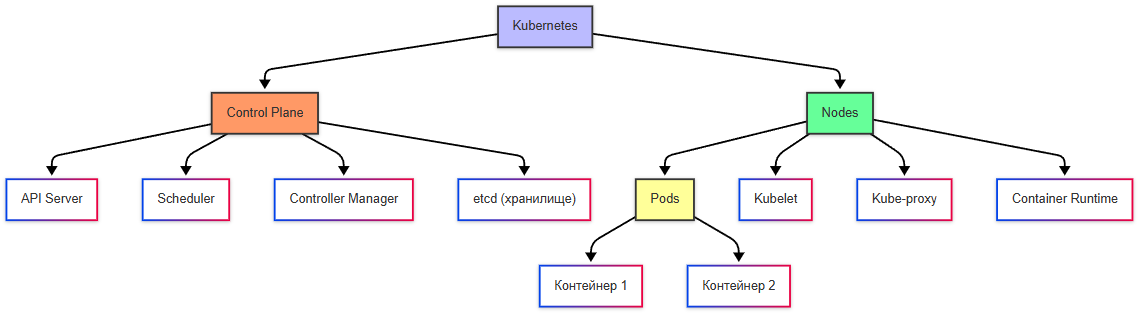
По официальному описанию компонентов кластер состоит из control plane и узлов (nodes).
Основные компоненты:
- Control Plane (плоскость управления) - управляет кластером, состоит из компонентов, таких как API Server, Scheduler, Controller Manager;
- Nodes (узлы) - физические или виртуальные машины, где запускаются контейнеры;
- Pods (поды) - наименьшая единица в Kubernetes. Под может содержать один или несколько контейнеров.
Контейнер собирается в под, поды собираются в рабочие узлы (ноды), ноды – это рабочие машины, которые, в свою очередь, собираются в кластер.
Кластер > Узел (нод) > Под (содержит контейнер)
Разбор:
- Кластер — логическая граница — API, etcd, scheduler и набор узлов под одним kubeconfig.
- Узел (Node) — машина (VM/bare metal) с kubelet, CRI и kube-proxy; на нём планируются Pod'ы.
- Pod — минимальная единица планирования; один или несколько контейнеров с общим network namespace.
- Контейнер внутри Pod — runtime-процесс из образа; Pod получает IP и тома, а не отдельный контейнер "сам по себе".
- Иерархия помогает читать
kubectl get nodes,podsи понимать, где искать сбой.
Play ITЗагрузка интерактивного демо…
Кластер – единая логическая система, состоящая из:
- узлов (нод, node) – физических или виртуальных машин, на которых развернуты контейнеры, узлы включают:
- Kubelet (агент, выполняющий команды дирижёра);
- Kube-proxy (обеспечивающий сетевую связность);
- Container Runtime (среду для запуска контейнеров).
- панели управления (control plane) – "дирижёр" кластера, управляющий нодами, включает:
- API Server (kubectl, входная точка для команд),
- Scheduler (планировщик, определяющий, на каком ноде запустить под),
- Controller Manager (следит за состоянием кластера),
- etcd – база данных конфигураций кластера.
Minikube
Docker Desktop включает в себя встроенный Kubernetes.
На персональном ПК устанавливается одноузловый кластер Minikube.
Minikube — это инструмент с открытым исходным кодом, предназначенный для локального запуска одноузлового кластера Kubernetes. Он позволяет разработчикам и администраторам тестировать, изучать и отлаживать приложения в окружении, максимально приближенном к реальному кластеру Kubernetes, без необходимости развертывания полноценной распределённой инфраструктуры.
Minikube создаёт виртуальную или контейнеризованную среду на локальной машине, внутри которой разворачивается упрощённый кластер Kubernetes. Архитектура включает:
Компоненты кластера:
- API Server — центральный компонент управления
- etcd — распределённое хранилище состояния кластера
- kubelet — агент, управляющий контейнерами на узле
- kube-proxy — сетевой прокси для сервисов
- Container Runtime — среда выполнения контейнеров (Docker, containerd и др.)
- CNI Plugin — сетевой плагин для организации pod-to-pod связи
Механизмы изоляции:
Minikube может использовать различные драйверы для создания изолированного окружения:
- VirtualBox, VMware, Hyper-V — гипервизоры
- Docker, Podman — контейнерные среды
- KVM, QEMU — аппаратная виртуализация Linux
Процесс установки и запуска включает в себя следующие процедуры:
- Установка Minikube — загрузка бинарного файла или использование пакетных менеджеров
- Выбор драйвера — определение среды изоляции (по умолчанию зависит от ОС)
- Инициализация кластера — создаёт виртуальную машину и разворачивает компоненты Kubernetes:
minikube start
Разбор:
minikube startподнимает одноузловый кластер Kubernetes в VM или контейнере на локальной машине.- Выбор драйвера (
--driver=docker,hyperv,kvm2) задаёт способ изоляции узла. - Внутри разворачиваются компоненты control plane и kubelet на одном "ноде".
- Команда обновляет
~/.kube/config, чтобы kubectl указывал на Minikube API. - Ресурсы CPU/RAM ограничены хостом; для тяжёлых workload увеличивают
--cpusи--memory. - Это учебный кластер: нет многоузловой отказоустойчивости control plane.
- Addons (Ingress, metrics-server) включают отдельно:
minikube addons enable ingress. - Остановка:
minikube stop; удаление:minikube delete— с очисткой локального состояния.
- Настройка kubectl — автоматическая конфигурация клиента для взаимодействия с локальным кластером
Технические ограничения:
- Одноузловой кластер — отсутствует распределённость и отказоустойчивость
- Ограниченные ресурсы — зависит от возможностей хостовой машины
- Упрощённая сетевая модель — может отличаться от production-сред
Работа с Kubernetes
★ Как работать с Kubernetes:
- подготовка – развернуть кластер, указав количество control plane и worker node, в отличие от Docker – здесь кластер, а не машина;
- разработка приложения;
- определение сервисов, подов, конфигурации, масштабирования;
- формирование манифестов (вместо Dockerfile используется YAML-манифест);
- сборка образа (docker build);
- публикация образа (docker push) в репозиторий;
- деплой — kubectl apply к манифесту (см. блок ниже) — Kubernetes скачает образ, создаст поды по
replicas, настроит сеть; - тестирование – в отличие от Docker, тестировать можно не один контейнер, а всё приложение целиком (включая все поды по списку, балансировку и сеть);
- деплой на продакшн.
Основные действия:
| Действие | Kubernetes |
|---|---|
| Запуск | kubectl apply к deployment.yaml — создаётся число подов из манифеста (команды в примере ниже). |
| Масштабирование | Определяется в манифесте YAML. Поддерживается автоматическое масштабирование. При сбое одного пода новый создаётся автоматически. |
| Сеть | Глобальная маршрутизация настраивается через YAML-манифесты с использованием сетевых плагинов: • Service — абстракция для доступа к подам: – ClusterIP (внутренний IP), – NodePort (порт на каждой ноде), – LoadBalancer (облачный балансировщик). • Ingress — управление маршрутизацией HTTP/HTTPS-трафика. • CNI (Calico, Flannel) — плагины для организации сети между подами на разных нодах. |
| Хранение данных | Используются облачные или локальные диски, настраиваемые через YAML-манифесты: • PersistentVolume (PV) — ресурс хранилища в кластере. • PersistentVolumeClaim (PVC) — запрос на использование хранилища от имени пода. • StorageClass — шаблон для динамического выделения томов (например, в облачной среде). |
| Обновление приложения | Управляется через YAML-манифесты: • Rolling Update — поэтапное обновление: новые поды с новой версией запускаются, старые удаляются после успешной проверки. Обеспечивает обновление без простоя. • Blue-Green Deployment — развёртывается полная копия приложения с новой версией, после проверки трафик переключается на неё одномоментно. |
| Отказоустойчивость | Обеспечивается на уровне подов: при сбое под автоматически пересоздаётся. |
| Динамическое масштабирование | Поддерживается (на основе метрик, таких как загрузка CPU или памяти), реализуется через Horizontal Pod Autoscaler (HPA). |
Официальная документация — карта разделов
Структура kubernetes.io/docs (курируемый навигатор — /tools/documentation/7):
| Раздел | Содержание | Язык |
|---|---|---|
| Концепции → Обзор | Что такое K8s, компоненты, API, объекты | RU |
| Настройка | Локально, managed, turnkey, kubeadm | RU (часть EN) |
| Установка инструментов | kubectl, Minikube, kubeadm | RU |
| Генерация сертификатов | PKI control plane вручную | EN |
| Кластерная архитектура | Узлы, контроллеры, HA | RU |
| Контейнеры | Образы, CRI, runtime | RU |
| Рабочие нагрузки | Pod, Deployment, Job… | RU |
| Services, Load Balancing, Networking | Service, Ingress, NetworkPolicy | EN |
| Storage | Volume, PV, PVC | EN |
| Configuration | ConfigMap, Secret | EN |
| Security | RBAC, SA, admission | EN |
| Policies | Quota, LimitRange, PSA | EN |
| Планирование и вытеснение | Scheduler, PriorityClass | RU |
| Администрирование кластера | Логи, addons, обновления | RU |
| Расширения | CRD, операторы | RU |
| Windows in Kubernetes | Windows-узлы | EN |
| Tasks | Пошаговые инструкции | EN |
| kubectl | Справочник CLI | EN |
Руководства для старта: Привет, Minikube, Основы Kubernetes.
Установка
Первый шаг в использовании Kubernetes — это его корректная установка. На странице "Настройка" описаны варианты: среда обучения (Minikube, kind), managed (GKE, EKS, AKS), turnkey и кастомный кластер (kubeadm). Процесс начинается с подготовки окружения, установки необходимых пакетов и конфигурации узла.
Подготовка системы
Прежде всего отключите swap (Kubernetes работает без него):
sudo swapoff -a
Разбор:
- Kubernetes (kubelet) ожидает предсказуемую память на узле; активный swap мешает учёту RAM и eviction.
swapoff -aотключает все swap-разделы и файлы до следующей перезагрузки.- Для постоянного отключения комментируют строки swap в
/etc/fstabи перезагружают узел. - На managed-кластерах (EKS, GKE) swap обычно уже отключён в образе узла.
- Minikube и Docker Desktop часто обходят требование на десктопе, но kubeadm на Linux — нет.
- Отключение swap не заменяет лимиты
requests/limitsдля подов. - При нехватке памяти kubelet вытесняет поды (eviction), а не полагается на swap.
- Включение swap после установки может привести к предупреждениям и нестабильному планированию.
Чтобы отключение сохранялось после перезагрузки, закомментируйте swap в /etc/fstab.
Container runtime (CRI)
Узлы Kubernetes запускают контейнеры через Container Runtime Interface (CRI) — чаще всего containerd или CRI-O. Docker Engine на узле нужен только если вы сознательно выбираете его как runtime; для сборки образов на рабочей станции Docker по-прежнему удобен.
На Ubuntu для kubeadm обычно устанавливают containerd:
sudo apt-get update
sudo apt-get install -y containerd
sudo mkdir -p /etc/containerd
containerd config default | sudo tee /etc/containerd/config.toml
sudo systemctl restart containerd
Разбор:
- containerd — типичный CRI-runtime на узлах Kubernetes; kubelet запускает поды через него.
- Пакет из репозитория дистрибутива ставит демон и unit
containerd.service. containerd config defaultгенерирует/etc/containerd/config.tomlс настройками по умолчанию.- В конфиге для kubeadm часто включают
SystemdCgroup = true(зависит от версии и ОС). systemctl restart containerdприменяет конфиг; без работающего CRI kubelet не стартует поды.- Сборка образов на узле не обязательна — образы тянет kubelet/CRI из registry.
- Docker Engine на worker для kubeadm 1.24+ не требуется, если runtime — containerd.
- Логи runtime:
journalctl -u containerd; диагностика подов —crictl psпри установленном плагине.
Установка kubeadm, kubelet и kubectl
Эти компоненты являются основными для работы Kubernetes.
Их можно установить через официальный репозиторий Kubernetes:
# Добавление официального GPG-ключа
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.30/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
# Добавление репозитория
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.30/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
# Установка
sudo apt-get update
sudo apt-get install -y kubeadm kubelet kubectl
Разбор:
- Репозиторий
pkgs.k8s.io— актуальный канал пакетов Kubernetes (с 2024 года вместоapt.kubernetes.io). - GPG-ключ в
/etc/apt/keyrings/проверяет подлинность пакетов изkubernetes.list. - kubeadm инициализирует control plane; kubelet — агент на каждом узле; kubectl — CLI к API.
- Версию в URL (
v1.30) согласуют на всех узлах кластера (kubelet, kubeadm, control plane). - После установки kubelet часто в
holdили не запущен доkubeadm init/join. kubectlможно ставить на рабочую станцию отдельно от узлов кластера.- Пины версий (
apt-mark hold) помогают избежать случайного обновления только kubelet. - Для production сверяют матрицу совместимости версий CRI, CNI и Kubernetes.
Для других дистрибутивов и версий Kubernetes — см. официальную документацию:
🔗 https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
В связи с переходом проекта Kubernetes на полностью независимую инфраструктуру, ** теперь у них новые официальные репозитории**:
→ https://pkgs.k8s.io/core:/stable:/v1.30/deb/ (для Debian/Ubuntu)
→ https://pkgs.k8s.io/core:/stable:/v1.30/rpm/ (для RHEL/CentOS/Rocky)
Репозитории apt.kubernetes.io и yum.kubernetes.io не функционируют с 4 марта 2024 года
Инициализация кластера
После установки компонентов инициализируйте control plane:
sudo kubeadm init
Разбор:
kubeadm initразворачивает control plane на первом узле — API Server, scheduler, controller-manager, etcd.- В конце выводит команду
kubeadm joinдля worker и путь к admin kubeconfig. - Перед init нужны отключённый swap, работающий containerd/CRI и согласованные версии пакетов.
- Pod CNI (Calico, Flannel и др.) ставят после init — без CNI поды
kube-systemне станут Ready. - Флаги
--pod-network-cidrзадают подсеть подов под выбранный CNI-плагин. - Для HA-control plane используют
kubeadm initс--control-plane-endpointи несколько masters. - Сброс кластера на узле:
kubeadm reset(осторожно в проде). - Worker подключают отдельной командой
kubeadm joinс токеном из вывода илиkubeadm token create.
Далее настройте kubectl для текущего пользователя (копирование kubeconfig из вывода kubeadm init).
После успешного развёртывания кластера следующий этап — описание приложения в формате YAML.
Kubernetes использует декларативный подход, где все параметры указываются в манифестах.
Рассмотрим пример развёртывания NGINX с тремя репликами, настройкой портов и проверками работоспособности. Сохраните манифест в deployment.yaml.
Код ITЗагрузка примера кода…
Разбор:
apiVersion: apps/v1,kind: Deployment— контроллер держит заданное число Pod'ов с шаблоном контейнера.replicas: 3— желаемое количество подов; ReplicaSet создаёт их с меткойapp: nginx.selector.matchLabelsдолжен совпадать сtemplate.metadata.labels, иначе Deployment не свяжет Pod'ы.image: nginx:1.27-alpine— фиксированный тег образа; пересборка не нужна для смены конфигурации.containerPort: 80— порт процесса в контейнере; Service укажетtargetPortна него.resources.requests/limitsпомогают Scheduler и kubelet ограничивать CPU/RAM на узле.livenessProbeперезапускает контейнер при "зависании";readinessProbeисключает под из Service до готовности.kubectl apply -f deployment.yamlсоздаёт или обновляет объект декларативно (reconcile loop).
Сохраните манифест Service в service.yaml — без него поды доступны только по IP внутри кластера:
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
type: ClusterIP
selector:
app: nginx
ports:
- port: 80
targetPort: 80
Разбор:
kind: Serviceдаёт стабильный виртуальный IP и DNS внутри кластера для набора Pod'ов.type: ClusterIP— доступ только из кластера; внешний трафик — через Ingress или LoadBalancer.selector.app: nginxсвязывает Service с Pod'ами Deployment по той же метке.port: 80— порт Service;targetPort: 80— порт контейнера в Pod (могут различаться).- kube-proxy (или CNI eBPF) обновляет правила при смене IP подов; клиенты ходят на имя Service.
- Полное DNS-имя:
nginx-service.<namespace>.svc.cluster.local. - Endpoints/EndpointSlice автоматически перечисляют IP готовых (ready) подов.
- Без Service обращение только по IP Pod'а — нестабильно при пересоздании.
selector.app должен совпадать с меткой в template.metadata.labels Deployment. Service даёт стабильный DNS (nginx-service, полное имя nginx-service.default.svc.cluster.local) и балансирует трафик между Pod'ами; kube-proxy (или eBPF-замена в CNI) обновляет правила при смене IP подов. Объекты Endpoints / EndpointSlice связывают Service с актуальными IP реплик.
kubectl apply -f deployment.yaml
kubectl apply -f service.yaml
kubectl get deploy,svc,pods
kubectl get endpoints nginx-service
Разбор:
kubectl apply -fотправляет манифесты в API Server; контроллеры приводят кластер к желаемому состоянию.- Сначала Deployment, затем Service — порядок важен для проверки, но API принимает и одним файлом.
kubectl get deploy,svc,podsпоказывает реплики, ClusterIP и статус подов в namespace по умолчанию.kubectl get endpoints nginx-serviceвыводит IP подов, попавших в балансировку Service (если readiness OK).- Опечатка в метках selector — Service без endpoints и "пустой" трафик.
- Контекст и namespace:
-n <ns>илиkubectl config set-context --current --namespace=.... applyидемпотентен: повторный запуск обновляет только изменённые поля spec.- Для отладки:
kubectl describe deployment/nginx-deploymentиkubectl logsпо label.
Этот манифест создаёт три реплики NGINX-подов, каждая из которых открывает порт 80. livenessProbe — "жив ли процесс"; при сбое kubelet перезапускает контейнер. readinessProbe — "готов ли принимать трафик"; пока проверка не прошла, Service не направляет запросы на под. Их не стоит путать — "живой", но ещё прогревающийся под должен падать по readiness, а не по liveness. requests резервируют ресурсы на узле; limits ограничивают пиковое потребление (на кластерах с LimitRange без requests под может не запуститься).
Масштабирование:
kubectl scale deployment/nginx-deployment --replicas=5
Разбор:
- Императивно меняет
spec.replicasDeploymentnginx-deploymentна пять Pod'ов. - ReplicaSet контроллер создаёт или удаляет Pod'ы, пока фактическое число не совпадёт.
- Эквивалент декларативному изменению
replicasв YAML иkubectl apply. - HPA при активном авт scaling может переопределить ручной scale через некоторое время.
- Масштабирование не обновляет образ — для релиза меняют
imageв spec template. - На узлах должно хватать CPU/RAM по
requests, иначе Pod'ы останутся Pending. kubectl scale --replicas=0останавливает workload без удаления Deployment.- Имя ресурса в формате
deployment/<name>или-f deployment.yaml.
Мониторинг кластера является важнейшим аспектом управления Kubernetes.
Команда kubectl cluster-info выводит базовые сведения о компонентах кластера, таких как адрес API-сервера и статус etcd.
kubectl cluster-info
Разбор:
- Показывает URL API Server и адреса основных сервисов control plane (если доступны с клиента).
- Подтверждает, что
kubectlнастроен на правильный контекст в~/.kube/config. - Для Minikube/kubeadm часто выводит
https://<ip>:6443control plane. - Не заменяет мониторинг: только базовая проверка связности с кластером.
- При ошибке TLS или auth проверяют сертификаты, токен и
kubectl config view. - Дополнительно:
kubectl cluster-info dump— большой дамп для поддержки (осторожно с секретами). - CoreDNS и addons в выводе могут отсутствовать, если не установлены или недоступны снаружи.
- На managed-кластерах endpoint может быть публичным load balancer API.
Например, выполнение команды может дать следующий результат:
Kubernetes control plane is running at https://192.168.99.100:8443
CoreDNS is running at https://192.168.99.100:8443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
Разбор:
- Пример вывода
kubectl cluster-info: URL API Server control plane. - Строка про CoreDNS — прокси-URL для доступа к DNS addon в
kube-system(в Minikube часто через туннель). - IP
192.168.99.100типичен для старых Minikube/VirtualBox; у вас будет свой адрес. - это иллюстрация успешной связности клиента с кластером.
- Если control plane "not running" — проверяют kubeconfig, firewall и состояние control plane.
Команда kubectl get nodes показывает список всех узлов кластера и их статус. Например (версия совпадает с установленным kubeadm, здесь — v1.30):
kubectl get nodes
Разбор:
- Список узлов кластера — имена, статус Ready/NotReady, роли, версия kubelet/Kubernetes.
STATUS Readyозначает, что kubelet отвечает и узел принимает поды (при достаточных ресурсах).ROLESпоказывает control-plane, worker или custom labels (node-role.kubernetes.io/*).VERSIONдолжна быть согласована в пределах поддерживаемого skew между control plane и nodes.- NotReady часто связан с CNI, диском, pressure (memory/disk) или остановленным kubelet.
-o wideдобавляет внутренние IP и ОС;--show-labels— метки для affinity/taints.- Узлы не создаёт kubectl — их добавляют
kubeadm joinили провайдер облака. - Cordoning:
kubectl cordon+drainперед обслуживанием узла.
Пример вывода:
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane 2d v1.30.0
node2 Ready <none> 2d v1.30.0
node3 Ready <none> 2d v1.30.0
Разбор:
- Пример таблицы
kubectl get nodes— имя узла, готовность, роль, возраст, версия kubelet/K8s. STATUS Ready— узел принимает поды;NotReady— проблема kubelet, CNI или ресурсов.ROLES control-planeуnode1— мастер/управляющий узел; у worker часто<none>илиworker.VERSION v1.30.0должна быть в допустимом skew относительно версии API Server.- Три узла — учебный кластер kubeadm: один control plane и два worker.
Если какой-либо узел находится в состоянии NotReady, это может свидетельствовать о проблемах с сетью, недоступностью ресурсов или ошибками в конфигурации.
Диагностика узла:
kubectl describe node <node-name>
kubectl get nodes
Разбор:
kubectl describe node <node-name>— события, taints, allocatable ресурсы, состояние условий (Ready, DiskPressure).- Помогает найти причину NotReady — kubelet, container runtime, сеть, нехватка места на диске.
- Повторный
get nodes— быстрая проверка после исправления CNI или перезапуска kubelet. - В describe видны Pod'ы на узле и лимиты — полезно при eviction и переполнении.
- Taints без подходящих tolerations блокируют планирование новых Pod'ов на узел.
kubectl debug node/...(в новых версиях) — временный под для диагностики хоста.- Для кластера с многими узлами фильтруют
-lпо меткам зон или пулов. - Логи kubelet на узле:
journalctl -u kubelet(Linux).
Таким образом, Kubernetes предоставляет комплексный набор инструментов для развёртывания и управления приложениями, начиная от базовой установки и заканчивая мониторингом и отладкой.
Инструменты и компоненты Kubernetes
Основные компоненты Kubernetes
Контрольная плоскость (Control Plane)
kube-apiserver: API-сервер для управления кластером.etcd: Распределённое хранилище данных кластера.kube-scheduler: Планировщик подов на узлы.kube-controller-manager— Управление контроллерами (например, ReplicaSet, Deployment).cloud-controller-manager: Интеграция с облачными провайдерами.
Узловые компоненты (Node Components)
kubelet: Агент, который управляет подами на узле.kube-proxy: Прокси для сетевого трафика между подами.Container Runtime— Среда выполнения контейнеров (например, containerd, CRI-O).
Управление ресурсами
Развертывание и масштабирование
Deployment: Управление состоянием приложений.StatefulSet: Для приложений с состоянием (например, базы данных).DaemonSet: Запуск пода на каждом узле (например, для мониторинга).Job/CronJob: Выполнение одноразовых или периодических задач.HPA (Horizontal Pod Autoscaler): Горизонтальное масштабирование подов.VPA (Vertical Pod Autoscaler): Вертикальное масштабирование (увеличение ресурсов).KEDA (Kubernetes Event-driven Autoscaling): Масштабирование на основе событий.
Хранилище
PersistentVolume (PV): Объём постоянного хранилища.PersistentVolumeClaim (PVC): Запрос на использование хранилища.StorageClass: Классы хранилищ для динамического provisioner'а.CSI (Container Storage Interface): Интерфейс для интеграции хранилищ.Longhorn: Распределённое блочное хранилище для Kubernetes.Rook: Оркестрация распределённых хранилищ (например, Ceph).
Сети и DNS
Сетевые компоненты
- CNI (Container Network Interface) : Интерфейс для сетевых плагинов.
Calico: Сетевой плагин с поддержкой сетевой политики.Flannel: Простой сетевой плагин.Weave Net: Сетевой плагин с шифрованием.
- Ingress : Управление входящим трафиком.
NGINX Ingress Controller.Traefik: Альтернатива NGINX.HAProxy Ingress: Высокопроизводительный контроллер.
- Service Mesh :
- Istio : Service Mesh для микросервисов.
- Linkerd : Лёгкий Service Mesh.
- NodeLocal DNS Cache : Локальный DNS-кэш для узлов.
Безопасность сети
NetworkPolicy: Ограничение трафика между подами.CoreDNS: DNS-сервер для Kubernetes.ExternalDNS: Синхронизация DNS-записей с сервисами.
Безопасность
Управление секретами
Secrets: Хранение чувствительных данных — справочник, раздел Secret.ConfigMaps: Хранение конфигураций.HashiCorp Vault: Централизованное управление секретами — Управление конфигурациями и окружениями.External Secrets Operator: Синхронизация секретов с внешними хранилищами — Управление конфигурациями и окружениями.
Политики безопасности
Pod Security Admission (PSA): встроенный механизм ограничений через метки Namespace (заменил PSP, удалён с Kubernetes 1.25).Kyverno: Политики безопасности для Kubernetes.Open Policy Agent (OPA): Фреймворк для политик (например, Gatekeeper).
RBAC
Role/ClusterRole: Определение прав доступа.RoleBinding/ClusterRoleBinding: Привязка ролей к пользователям или группам.
Мониторинг и логирование
Мониторинг
Zabbix— Мониторинг серверов, SNMP, SLA — практикум.Prometheus: Сбор метрик — практикум, справочник.Grafana: Визуализация метрик — практикум, шаг 4, справочник.Metrics Server: Сбор метрик для HPA.Kubernetes Event Exporter: Экспорт событий Kubernetes.Loki: Система сбора и анализа логов — практикум, шаг 7.Tempo: Система распределённой трассировки — практикум, шаг 7.
Логирование
EFK Stack (Elasticsearch, Fluentd, Kibana): Сбор и анализ логов.Fluent Bit: Лёгкий агент для сбора логов.
Управление кластером
Оптимизация и балансировка
Descheduler: Перераспределение подов для оптимизации ресурсов.Cluster Autoscaler: Автоматическое масштабирование узлов.Node Affinity/Anti-Affinity: Управление размещением подов.
Node Affinity/Anti-Affinity
Разбор:
- Заголовок раздела, а не исполняемая команда: affinity и anti-affinity задаются в YAML Pod/Deployment.
nodeAffinity— привязка подов к узлам с нужными метками (зона, тип железа, GPU).podAntiAffinity— разнос реплик по разным узлам (отказоустойчивость, изоляция noisy neighbor).- В манифесте используют
affinity.nodeAffinity/podAntiAffinityвspec.template.spec. - Для автоматического перераспределения подов смотрят также Descheduler (упомянут в списке инструментов ниже).
Облачные провайдеры
AWS EKS: Управляемый Kubernetes в AWS.Google GKE: Управляемый Kubernetes в Google Cloud.Azure AKS: Управляемый Kubernetes в Azure.OpenShift: Платформа на базе Kubernetes от Red Hat.
CI/CD
ArgoCD: GitOps-инструмент для развертывания приложений.Tekton: Фреймворк для CI/CD.Jenkins X: CI/CD для Kubernetes.
Custom Resource Definitions (CRD)
CRD и операторы
Custom Resource Definition (CRD): Расширение Kubernetes для пользовательских ресурсов.Operator Framework: Разработка операторов для автоматизации.Prometheus Operator: Управление Prometheus через CRD.Cert-manager: Автоматизация управления сертификатами TLS.Istio Operator: Управление Istio через CRD.
Дополнительные инструменты
Управление конфигурацией
Helm: Менеджер пакетов для Kubernetes.Kustomize: Инструмент для настройки манифестов.
Тестирование
kubectl: Командная строка для взаимодействия с кластером.kubebuilder: Фреймворк для создания операторов.Sonobuoy: Инструмент для тестирования кластера.
Анализ производительности
Sysdig: Мониторинг и безопасность.Datadog: Мониторинг и аналитика.
Бэкапы
Velero: Инструмент для резервного копирования кластера.WAL-G: Инструмент для бэкапов баз данных.
Хранилище
Restic: Инструмент для резервного копирования данных.MinIO: Объектное хранилище, совместимое с S3.
Диагностика
Lens: Графический интерфейс для Kubernetes.Octant: Инструмент для анализа кластера.
Расширенные инструменты
Мультикластерное управление
Rancher: Управление несколькими кластерами.Deckhouse: Платформа для управления Kubernetes.
Инструменты для разработчиков
Minikube: Локальный кластер для разработки.Kind (Kubernetes IN Docker): Локальный кластер в Docker.Skaffold: Инструмент для разработки приложений в Kubernetes.
Сервисы и интеграции
Service Catalog: Интеграция с внешними сервисами.
Service Catalog
Разбор:
-
Service Catalog — исторический Open Service Broker API в Kubernetes для подключения managed-сервисов из каталога.
-
Проект в upstream Kubernetes deprecated; в новых кластерах чаще используют операторы провайдера или CRD.
-
Строка в блоке — маркер подраздела списка инструментов, не команда CLI.
-
Аналоги сегодня — Crossplane, Terraform, cloud-specific операторы (RDS, Cloud SQL).
-
Knative в следующем пункте — отдельная serverless-платформа поверх K8s, не замена Service Catalog.
Knative: Платформа для serverless-приложений.
Helm
Helm — это менеджер пакетов для Kubernetes.
Он упрощает развертывание и управление приложениями в Kubernetes-кластере с помощью шаблонов (чартов).
Helm-чарт — это пакет, который содержит все необходимые файлы для развертывания приложения в Kubernetes. Чарт включает:
templates/- шаблоны манифестов Kubernetes (deployment,service,configmapи т.д.).values.yaml- файл с переменными, которые могут быть переопределены при установке.Chart.yaml- метаданные о чарте (название, версия, описание).charts/- зависимости от других чартов.
Helm используется для автоматизации развертывания приложений в Kubernetes. Вместо ручного создания YAML-файлов Helm позволяет использовать параметризованные шаблоны, управлять зависимостями между компонентами приложения, а также обновлять и откатывать версии приложений.
Как работает Helm:
- Пользователь создает или загружает Helm-чарт.
- Helm компилирует шаблоны в YAML-файлы Kubernetes.
- Эти файлы применяются к кластеру через
kubectl.
OpenShift
OpenShift — это платформа контейнеризации, основанная на Kubernetes. Она предоставляет дополнительные функции для корпоративных пользователей, такие как встроенный реестр контейнеров, графический интерфейс управления (Web Console), инструменты CI/CD, потоковая передача логов и мониторинг, а также поддержка безопасности и соответствия стандартам. В отличие от "чистого" Kubernetes, OpenShift предоставляет больше готовых решений и включает встроенные инструменты для разработчиков.
HAProxy Ingress
HAProxy Ingress — это контроллер входящего трафика (Ingress Controller) для Kubernetes, основанный на HAProxy. Он маршрутизирует внешний трафик к сервисам внутри кластера.
Longhorn
Longhorn — это распределенная система хранения данных для Kubernetes. Она предоставляет управление томами (Persistent Volumes) с поддержкой репликации, мониторинг состояния томов и автоматическое восстановление данных при сбоях.
Affinity
Affinity (сродство) — это механизм в Kubernetes, который позволяет назначать поды на определенные узлы (nodes) на основе заданных условий. Например, размещение подов на узлах с определенной меткой или группировка подов вместе для улучшения производительности.
Anti-affinity
Anti-affinity (анти-сродство) — это противоположный механизм, который предотвращает размещение подов на одних и тех же узлах. Это полезно для разделение подов по разным узлам и предотвращения перегрузки одного узла.
Security Context
Security Context — это механизм в Kubernetes, который позволяет задавать параметры безопасности для подов или контейнеров. Он используется для контроля прав доступа, привилегий и других аспектов безопасности.
Уровни настройки:
- На уровне Pod параметры применяются ко всем контейнерам в поде.
- На уровне контейнера параметры применяются только к конкретному контейнеру.
Основные параметры:
runAsUser: указывает UID пользователя, от имени которого запускается контейнер.runAsGroup: указывает GID группы.fsGroup: задает группу для файловой системы.privileged: разрешает или запрещает привилегированный режим.readOnlyRootFilesystem: делает файловую систему контейнера доступной только для чтения.capabilities: управляет возможностями Linux (например, добавление/удаление прав).
Hostpath-provisioner
Hostpath-provisioner — это динамический provisioner для Kubernetes, который создает Persistent Volumes (PV) на основе локальных директорий узлов (hostPath). Применяется при развёртывании в одноконтроллерных кластерах (например, Minikube).
HPA
HPA — это встроенный механизм Kubernetes для автоматического горизонтального масштабирования подов на основе метрик (например, CPU, память, пользовательские метрики). HPA мониторит метрики через Metrics Server. На основе заданных целевых значений (например, 50% CPU) увеличивает или уменьшает количество реплик пода.
KEDA
KEDA (Kubernetes Event-driven Autoscaling)— это инструмент для автоматического масштабирования приложений в Kubernetes на основе событий. В отличие от Horizontal Pod Autoscaler (HPA), который масштабирует поды на основе метрик (например, CPU или памяти), KEDA использует внешние события (например, количество сообщений в очереди). KEDA работает как Custom Resource Definition (CRD) и легко интегрируется.
Descheduler
Descheduler — это инструмент для перераспределения подов в Kubernetes-кластере. Он помогает оптимизировать использование ресурсов и равномерно распределять нагрузку между узлами.
NodeLocal DNS Cache
NodeLocal DNS Cache — это компонент Kubernetes, который улучшает производительность DNS-запросов за счет кэширования их на уровне узла.
DNAT
DNAT — это метод трансляции сетевых адресов, при котором изменяется адрес назначения пакета. Это используется для маршрутизации трафика на внутренние серверы через внешний IP-адрес, к примеру назначение внешних IP-адресов для Kubernetes Services типа LoadBalancer.
CoreDNS
CoreDNS — это гибкий DNS-сервер, используемый в Kubernetes для разрешения доменных имен внутри кластера. CoreDNS заменил kube-dns как стандартный DNS-сервер в Kubernetes.
Kubernetes Event Exporter
Kubernetes Event Exporter — это инструмент для экспорта событий Kubernetes в системы логирования или мониторинга (например, Elasticsearch, Loki, Prometheus). Основные функции - сбор событий из кластера (например, создание подов, ошибки), выборка событий по типу, объекту или другим параметрам и отправка данных в различные системы.
Cert-manager
Cert-manager — это инструмент Kubernetes для автоматического управления сертификатами TLS. Он позволяет получать, обновлять и применять сертификаты из таких источников, как Let's Encrypt.
Custom Resource Definition (CRD)
Custom Resource Definition (CRD) — это механизм Kubernetes, который позволяет пользователям создавать собственные типы ресурсов. CRD расширяет функциональность Kubernetes, позволяя добавлять новые объекты для управления специфическими задачами.
Как работает:
- Пользователь определяет новый тип ресурса через CRD.
- Kubernetes API начинает поддерживать этот тип.
- Пользователи могут создавать, изменять и удалять экземпляры этого ресурса.
TLS-сертификаты для Ingress и Pod обычно лежат в объекте Secret типа kubernetes.io/tls (или создаются оператором cert-manager). Подробно: Справочник — Secret.
Deckhouse
Deckhouse — это платформа для управления Kubernetes-кластерами, разработанная компанией Flant. Она предоставляет инструменты для автоматизации развертывания, масштабирования и мониторинга кластеров. Модули console (веб-UI), Commander (мультикластер), werf (CI/CD) и типичные связки с корпоративным доступом (SAML, VPN) — в Корпоративный доступ, SSO и платформенные инструменты.
PrometheusRule
PrometheusRule — это Custom Resource Definition (CRD) в Kubernetes, используемый для определения правил алертинга и записи метрик в Prometheus.
Alerting Rules: правила для генерации алертов на основе метрик.Recording Rules: правила для предварительной агрегации метрик.Интеграция с Kubernetes: управление правилами через Kubernetes API.
K8s-проекты и инструменты конфигурации
После базовых манифестов (Deployment, Service, ConfigMap) конфигурацию обычно структурируют по средам (dev, staging, prod): общее ядро в base/, отличия — в overlays или в values-prod.yaml.
| Инструмент | Идея | Когда удобен |
|---|---|---|
| Kustomize | Патчи к YAML без шаблонов, kubectl apply -k | Прозрачные diff'ы, мало условной логики |
| Helm | Чарты с Go-шаблонами и values.yaml | Пакеты, много параметров, готовые чарты Bitnami и др. |
Подробные примеры (Helm, HPA, Ingress, anti-affinity): Реализация Kubernetes. Поля YAML, RBAC, storage, NetworkPolicy: Справочник по Kubernetes.
★ ReplicaSet. Deployment управляет ReplicaSet, тот создаёт Pod'ы с нужными метками. Отдельный манифест ReplicaSet в учебных сценариях почти не пишут.
Минимальный overlay Kustomize:
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
resources:
- ../../base
patches:
- path: deployment-patch.yaml
Разбор:
- Kustomize описывает, как собрать манифесты из
baseи наложить патчи для окружения (dev/staging/prod). resourcesперечисляет каталог или файлы базы; без них overlay нечего патчить.patches(илиpatchesStrategicMerge) меняют поля Deployment, Service и др. без копирования всего YAML.apiVersion: kustomize.config.k8s.io/v1beta1,kind: Kustomization— служебный объект, не ресурс в кластере.- Сборка:
kubectl apply -k overlays/prod— Kustomize генерирует итоговый YAML и передаёт в API. - Отличие от Helm: нет Go-шаблонов в чарте; правки прозрачнее в diff Git.
- Один репозиторий — несколько overlays с разными
replicas, образами, ConfigMap. deployment-patch.yamlобычно задаёт только отличия (например,replicasилиimagetag).
Практика на Windows: Первые шаги.
Структура каталогов base/ + overlays/, примеры Helm-чартов и HPA — в Реализация Kubernetes. GitOps (Argo CD), Helmfile и гибридные схемы — в справочнике.
Рекомендации по проектированию K8s-проектов
- Единственный источник истины — вся конфигурация должна храниться в системе контроля версий (Git), за исключением секретов (которые должны управляться через Vault, External Secrets Operator и т.п.).
- Разделение обязанностей — базовая логика и окружение должны быть разделены. Изменение кода не должно требовать изменения конфигурации и наоборот.
- Воспроизводимость — любой разработчик по инструкции из
README.mdдолжен быть способен развернуть приложение локально или в тестовом кластере. - Минимизация кастомизации — избегайте сложных шаблонов и скриптов там, где можно обойтись стандартными Kubernetes-ресурсами. Чем проще конфигурация — тем надёжнее её эксплуатация.
- Документирование — каждый параметр в
values.yamlилиkustomization.yamlдолжен быть снабжён комментарием. ХорошийREADME.mdдолжен объяснять, как собрать, развернуть и обновить приложение, а также как добавить новое окружение. - Фиксированные теги образов — в манифестах указывайте версию (
nginx:1.27-alpine), а неlatest.
Docker Swarm и Kubernetes — когда что выбирать
Обе системы решают задачу оркестрации, но дают разный уровень контроля и сложности эксплуатации.
| Критерий | Docker Swarm | Kubernetes |
|---|---|---|
| Порог входа | Низкий, быстрый старт | Выше, больше сущностей и концепций |
| Скорость пилота | Очень высокая | Средняя |
| Гибкость для production | Базовая | Высокая |
| Экосистема | Компактная | Очень широкая (операторы, GitOps, policy, service mesh) |
| Тонкая настройка сети и политик | Ограниченная | Богатая (NetworkPolicy, ingress-классы, CNI) |
| Подходящий масштаб | Малые и средние кластеры | Средние и крупные, мультикомандные платформы |
Практическая развилка выглядит так:
- Для быстрого внутреннего сервиса и небольшой команды удобно стартовать со Swarm.
- Для долгоживущей платформы с несколькими командами и сложной безопасностью обычно выбирают Kubernetes.
- Для учебного стенда и локальной отладки подходит Kubernetes в Docker Desktop, потому что это переносит вас к production-практикам.
Пошаговая локальная практика находится в статье Первые шаги, а прод-подобный стек и шаблоны развёртывания разобраны в Реализация Kubernetes.
Типичные ошибки при переходе к оркестрации
На старте команды часто повторяют одни и те же ошибки. Их лучше закрыть заранее как инженерный чек-лист.
- Хранение состояния в контейнере без томов.
Симптом — после пересоздания пода пропадают данные. Решение: PV/PVC, резервные копии и восстановление. - Отсутствие
requests/limits.
Симптом — поды "вытесняют" друг друга, нестабильная производительность. Решение: задавать ресурсы явно на каждый workload. - Единый namespace для всего.
Симптом — сложнее управлять доступом и квотами. Решение: разделять окружения и команды по namespace. - Секреты в открытом YAML или
.envв репозитории.
Решение — Secrets, External Secrets Operator, KMS/Vault. - Отсутствие readiness/liveness probes.
Симптом — трафик идёт в нездоровые поды. Решение: обязательные проверки для каждого HTTP/worker-сервиса. - Нет стратегии наблюдаемости.
Решение — метрики, логи и алерты с первого дня, даже для "маленького" проекта.
Практики хранения секретов, базовая модель рисков и инциденты подробнее рассмотрены в Информационная безопасность.
Практический кейс — отказ одного узла в кластере
Сценарий помогает понять пользу оркестрации на языке реальных последствий.
Исходные условия:
- есть три узла кластера;
- сервис каталога работает в трёх репликах;
- входящий трафик идёт через балансировщик.
Что происходит при отказе одного узла:
- Узел перестаёт отвечать health-check.
- Планировщик отмечает потерю части реплик.
- Контроллеры запускают недостающие поды на доступных узлах.
- Балансировщик продолжает направлять трафик на живые реплики.
Инженерная польза:
- сервис сохраняет доступность для пользователей;
- команда устраняет причину отказа без срочной "ручной миграции" контейнеров;
- архитектура масштабируется предсказуемо при росте нагрузки и при сбоях.
Этот же сценарий можно воспроизвести локально в упрощённом виде через масштабирование и остановку подов в Первые шаги.
Чек-лист перехода от Docker к оркестрации
Перед переходом в кластерный режим удобно проверить базовые условия:
- все сервисы собираются в воспроизводимые образы с фиксированными тегами;
- stateful-компоненты используют тома и резервное копирование;
- конфигурация вынесена из образов в переменные окружения, ConfigMap и Secrets;
- у сервисов есть health-check и понятная стратегия рестартов;
- команда понимает маршрут логов, метрик и алертов.
Когда этот минимум закрыт, Kubernetes даёт заметный выигрыш в управляемости и надёжности.
Уточнение инструкций установки
Актуальные репозитории пакетов и команды установки kubeadm / kubelet / kubectl приведены выше в разделе Установка kubeadm, kubelet и kubectl. Версию в URL (v1.30 и т.д.) при необходимости замените на текущую стабильную из документации Kubernetes.
Базовый разбор HTTP и HTTPS находится в отдельной статье — HTTP как основа веб-интеграций.