Масштабирование микросервисных систем
Интернет-магазин в пик распродажи получает в десять раз больше запросов, чем в обычный вторник. Если сервер один и его мощности не хватает, страницы открываются медленно, оплата зависает, поддержка тонет в жалобах. Масштабирование — ответ на вопрос "как сделать так, чтобы система выдержала рост нагрузки без переписывания с нуля". В этом материале — базовые понятия, виды масштабирования, порядок работ и связь с балансировкой нагрузки, микросервисной архитектурой и контейнеризацией.
Практический маршрут по разделу — в введении "Микросервисы и интеграция".
После этой статьи логично перейти к первым шагам к микросервисам и архитектуре MSA.
Масштабирование
Что такое масштабируемость
Масштабируемость — это способность системы справляться с ростом нагрузки (пользователей, данных, запросов) без заметного падения производительности — время ответа API остаётся в пределах SLA, очереди не растут бесконечно, ошибки 503 не становятся нормой.
Масштабирование — это сам процесс увеличения мощности системы, чтобы она выдерживала эту нагрузку — добавить ядра, поднять ещё один экземпляр сервиса, включить кэш, разнести базу по шардам.
Так, систему разработали, протестировали, развернули. Но прогресс не стоит на месте, она "выстрелила", доходы увеличились, появились новые цели, бизнес-требования, да и новые правила рынка.
Данные увеличиваются в объёмах, нагрузка увеличивается, а весь огромный код в один проект уместить тяжеловато. Если программа изначально не была рассчитана на расширение, придётся переписывать. Именно поэтому в какой-то момент многие системы в 2010-х годах претерпели сильные реформы — переход с монолита на сервисы, вынос БД, CI/CD. Сейчас такие системы чаще развиваются плавно: масштабируют узкое место, а не всё приложение целиком.
| Понятие | Вопрос, на который отвечает |
|---|---|
| Масштабируемость | "Выдержит ли система завтрашний трафик?" |
| Масштабирование | "Что мы делаем сегодня, чтобы завтра выдержала?" |
| Узкое место (bottleneck) | "Что именно ломается первым — CPU, диск, сеть, БД?" |
Play ITЗагрузка интерактивного демо…
Типичный масштабируемый API-стек включает балансировщик перед несколькими экземплярами приложения, кэш для горячих данных, отдельный слой для статики (CDN), реплики базы и мониторинг (Практикум Prometheus и Grafana, Практикум Zabbix, теория). На диаграмме выше можно переставить узлы и прикинуть, куда пойдёт трафик при добавлении второго и третьего инстанса API.
Виды масштабирования
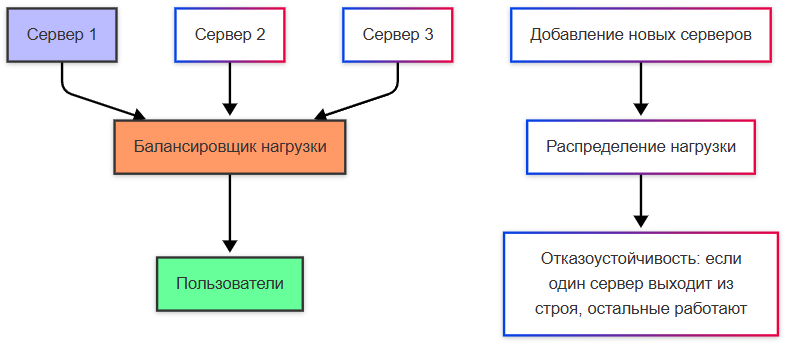
Горизонтальное масштабирование (scale out) — добавление новых экземпляров компонентов системы (серверов, узлов, контейнеров). Если один сервер не справляется с нагрузкой, поднимают ещё два-три с тем же образом приложения и ставят перед ними балансировщик.
Плюсы горизонтального подхода:
- ресурсы добавляют постепенно (сначала 2 инстанса, потом 4);
- при падении одного узла остальные продолжают обслуживать трафик;
- удобно сочетается с Kubernetes HPA и облачным autoscaling.
Минусы и условия:
- приложение должно быть stateless на уровне HTTP-слоя (сессии — в Redis, файлы — в S3, а не на диске одного pod);
- нужна согласованность данных (репликация БД, идемпотентные обработчики очередей);
- сложнее отладка: один запрос проходит через балансировщик и один из N инстансов.
Пример. API заказов обрабатывает 800 RPS на одном pod; p95 latency растёт. Деплой увеличивают replicas — 3, балансировщик распределяет запросы round-robin — каждый pod видит ~270 RPS, latency возвращается в норму.
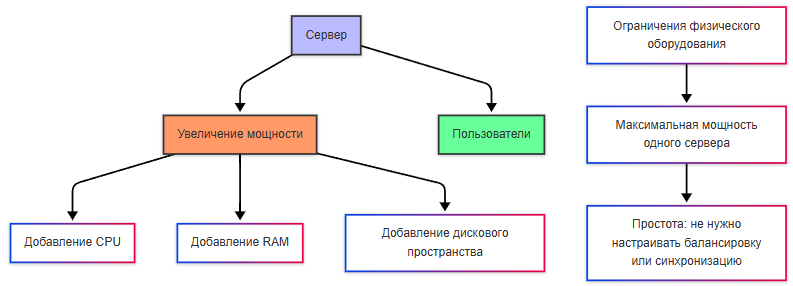
Вертикальное масштабирование (scale up) — увеличение мощности существующего сервера — больше vCPU, RAM, быстрее диск (NVMe вместо HDD). Архитектура не меняется, балансировщик не обязателен, синхронизация между узлами не нужна.
Плюсы:
- быстрый способ "потушить пожар" на этапе MVP;
- проще для legacy-монолита, который сложно разделить на инстансы.
Минусы:
- потолок железа одной машины (даже у крупных VM есть лимит);
- дороже на единицу производительности на больших масштабах;
- единая точка отказа — если сервер недоступен, недоступна вся система.
Пример. PostgreSQL на сервере 4 vCPU / 16 GB RAM упирается в CPU при отчётах. Временно увеличивают тариф до 8 vCPU / 32 GB — отчёты ускоряются, пока не внедрят read-replica или шардирование (NoSQL и распределённые БД — отдельная тема).
На практике команды комбинируют оба подхода: сначала scale up узкого места (часто БД), параллельно готовят scale out приложения и асинхронную обработку для пиков.
| Критерий | Горизонтальное | Вертикальное |
|---|---|---|
| Отказоустойчивость | Выше (несколько узлов) | Ниже (один узел) |
| Сложность внедрения | Выше (LB, сессии, деплой) | Ниже |
| Потолок роста | Практически не ограничен кластером | Ограничен одной машиной |
| Типичный инструмент | Kubernetes, Docker Swarm, облачные ASG | Увеличение тарифа VM |
Порядок масштабирования
Play ITЗагрузка интерактивного демо…
Как масштабируют систему?
- Определение узкого места (bottleneck). Смотрят метрики — CPU, RAM, disk I/O, сеть, latency БД, длина очереди в RabbitMQ или Kafka. Важно отличить "не хватает железа" от "медленный SQL-запрос" или "N+1 в ORM" — иначе масштабирование только размажет проблему по большему числу серверов. Подробнее про нагрузочные проверки — тестирование под нагрузкой.
- Выбор подхода. Если один сервер на пределе по CPU/RAM и приложение готово к нескольким инстансам — горизонтальное масштабирование. Если запас есть, но не хватает одного ресурса на узле (например, памяти у БД) — сначала вертикальное. Для отдельного микросервиса масштабируют только его, не весь монолит.
- Реализация. Добавляют серверы или pod'ы, настраивают балансировщик, проверяют репликацию данных, выносят сессии и кэш, обновляют лимиты в оркестраторе. Деплой — через CI/CD, чтобы новые инстансы поднимались предсказуемо.
- Тестирование. После изменений гоняют нагрузочный сценарий (k6, JMeter, Gatling) и сравнивают p95 latency, error rate и стоимость инфраструктуры до и после. Цель — выполнение SLA при том же или меньшем бюджете.
Нагрузка при масштабировании должна как-то распределяться. В горизонтальном масштабировании, она распределяется между несколькими серверами или узлами. Это делается с помощью балансировщика нагрузки , который направляет входящие запросы на разные серверы. Если используется база данных, она может быть либо централизованной (одна база для всех серверов), либо распределенной (разные серверы работают с разными частями данных).
Вертикальное масштабирование сохраняет нагрузку на одном сервере, но он становится более производительным за счет увеличения ресурсов.
При масштабировании, кстати, важно учитывать и зонирование систем. К примеру, может быть часть, которая публичная, а часть, которая должна быть закрытой. Обычно можно встретить три зоны - внешняя (ненадёжная) сеть, демилитаризованная (изолированная промежуточная буферная зона) и внутренняя (корпоративная, с самыми высокими требованиями к безопасности). Внешняя часть - это всегда посторонний интернет, словой, любой пользователь. Демилитаризованная зона содержит серверы, которые должны быть доступны извне (например, сайт, геопортал). Файрволы будут контролировать трафик. А внутренняя сеть же имеет самые строгие ограничения, например, веб-сервер может обращаться к базе данных только по определённому порту и с аутентификацией.
Когда система масштабируется, обычно используется кластеризация, которая образует группу серверов (узлов), работающих вместе, допустим как единая система для хранения и обработки данных, что повышает надёжность, производительность, доступность, позволяет распределять нагрузку между узлами, например, репликацией или шардированием. Некоторые веб-сервера, допустим, можно объединять в веб-фермы, которые будут работать совместно для обслуживания запросов к веб-приложению - тогда запросы будут поступать на балансировщик нагрузки, который будет распределять запросы между серверами в ферме. Все серверы обычно содержат одинаковую копию приложения, и если один сервер упал, другие продолжат работать.
Веб-серверы расположить можно в демилитаризованной зоне и они будут работать как веб-ферма, а базу данных в защищённой внутренней сети и она будет работать в кластере для отказоустойчивости. Сегментация сети и основы информационной безопасности дополняют картину масштабирования: рост узлов не должен означать рост поверхности атаки без firewall и политик доступа.
См. также
- Балансировка нагрузки — алгоритмы RR, least connections, HAProxy
- Архитектура микросервисов (MSA) — декомпозиция и независимое масштабирование сервисов
- Go для микросервисов — типичный стек для высоконагруженных API
- Контейнеризация и оркестрация — деплой множества экземпляров
- Сеть и интернет — DNS, CDN, маршрутизация трафика