Машинное обучение
Машинное обучение
Что такое машинное обучение?
Машинное обучение (Machine Learning, ML) — это область искусственного интеллекта, которая разрабатывает алгоритмы, способные извлекать знания из данных. Вместо явного программирования правил поведения, система самостоятельно находит закономерности в предоставленной информации и строит модели для решения задач.
Машинное обучение позволяет компьютерам адаптироваться к новым данным без изменения исходного кода программы. Это достигается через процесс обучения, в котором модель анализирует примеры и корректирует свои внутренние параметры.
Обучение нейросетей — это процесс настройки весов и параметров сети для выполнения конкретной задачи.
Это автоматическое извлечение знаний из данных без явного программирования правил.
Если стартовая точка — уже обученная модель, выбирают между трансферным обучением, fine-tuning, мультизадачным и федеративным подходом.
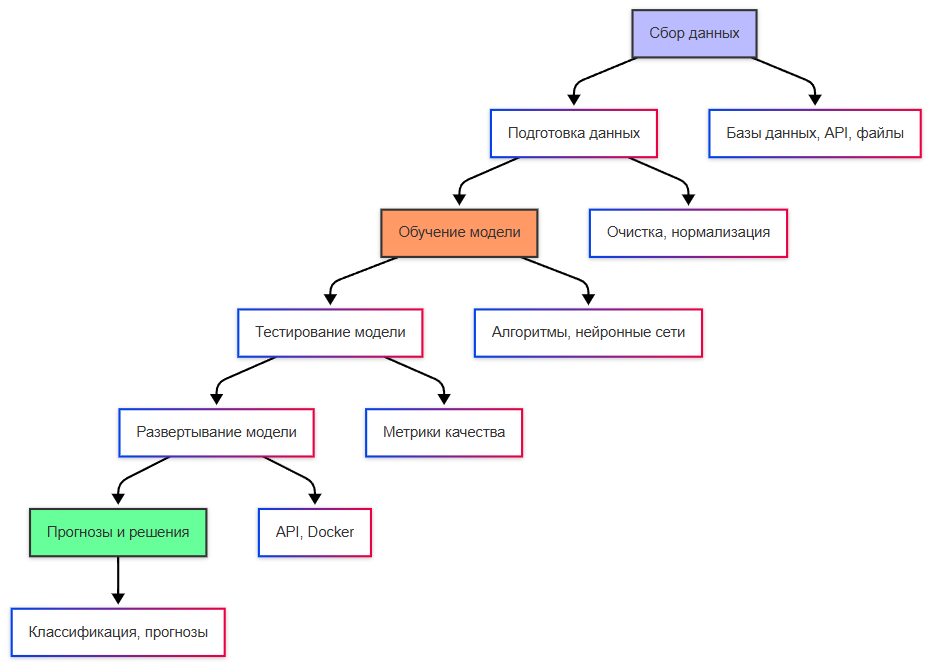
Сбор данных → очистка и признаки → разбиение train/validation/test → выбор алгоритма и гиперпараметров → оценка на отложенной выборке → деплой. Подробнее для новичков — Категории обучения и стек; табличный пример — Мельбурн.
Типы машинного обучения
Машинное обучение делится на четыре основных подхода в зависимости от того, как предоставляются данные для обучения:
- Обучение с учителем (supervised learning) — модель обучается на парах входных данных и целевых значений.
- Обучение без учителя (unsupervised learning) — модель ищет скрытые паттерны в данных без целевых меток.
- Полуконтролируемое обучение (semi-supervised) — часть данных размечена, часть нет; см. ниже.
- Обучение с подкреплением (reinforcement learning) — модель учится на основе взаимодействия с окружающей средой и получения наград.
Play ITЗагрузка интерактивного демо…
Play ITЗагрузка интерактивного демо…
Обучение с учителем
Обучение с учителем — это метод, при котором модель обучается на размеченных данных. Каждый пример входных данных сопровождается правильным ответом или меткой. Модель учится предсказывать выходные значения для новых, ранее неизвестных данных.
Примеры задач обучения с учителем:
- Классификация — определение категории объекта (спам или не спам, кошка или собака)
- Регрессия — предсказание числового значения (цена недвижимости, температура)
Обучение без учителя
Обучение без учителя — это метод, при котором модель работает с неразмеченными данными. Цель состоит в обнаружении скрытых структур, паттернов или группировок в информации.
Примеры задач обучения без учителя:
- Кластеризация — группировка похожих объектов
- Снижение размерности — сжатие данных с сохранением важной информации
- Обнаружение аномалий — выявление необычных паттернов
Полуконтролируемое обучение
Полуконтролируемое обучение — гибрид: в выборке есть и размеченные, и неразмеченные примеры. Разметка дорогая (медицина, право, промышленный контроль), а сырых данных много.
Типичный сценарий: обучить модель на размеченной части, с высокой уверенностью псевдоразметить неразмеченные строки и дообучить; либо итеративно добавлять в train только объекты выше порога confidence. Гарантий улучшения нет — нужна validation. Обзор категорий и Q-обучения — Категории обучения и стек.
Обучение с подкреплением
Обучение с подкреплением — это метод, при котором агент учится принимать решения через взаимодействие с окружающей средой. Агент получает награды за правильные действия и штрафы за неправильные, постепенно оптимизируя свою стратегию поведения. В классификации ИИ это близко к обучающемуся агенту с критиком и стандартом производительности — см. Типы интеллектуальных агентов.
Примеры применения обучения с подкреплением:
- Игровые агенты (шахматы, го, видеоигры)
- Робототехника и автономное управление
- Торговые алгоритмы на финансовых рынках
Мини-пример — классификация от "А" до "Г"
Типичный цикл ML на табличных данных: разделить выборку → обучить → оценить на тесте.
Код ITЗагрузка примера кода…
Ожидаемо: accuracy близка к 1.0 на Iris — набор простой. На реальных данных метрики ниже; важно смотреть не только accuracy, но и precision/recall при дисбалансе классов.
Датасеты и данные
Что такое датасет?
Датасет — это структурированный набор данных, используемый для обучения и оценки моделей машинного обучения. Датасет содержит информацию, необходимую для решения конкретной задачи, в формате, подходящем для обработки алгоритмами.
Данные важно разделять по типам - сложно организовать обучение с разными типами, беспорядочно перемешанными. При обучении, главное - понять, какие бывают типы (табличные, текст, изображения, временные ряды) и откуда их брать (встроенные датасеты, Kaggle, ETL-процессы).
Датасеты могут включать:
- Табличные данные (числа, категории)
- Текстовые документы
- Изображения и видео
- Аудиозаписи
- Временные ряды
Структура датасета
Датасет обычно разделяется на три части:
Обучающий набор — основная часть данных, используемая для обучения модели. Модель анализирует эти данные и настраивает свои параметры для минимизации ошибок.
Валидационный набор — промежуточный набор данных, используемый для настройки гиперпараметров модели и предотвращения переобучения. Модель не обучается на этих данных, но они помогают оценить качество во время обучения.
Тестовый набор — финальный набор данных, используемый для объективной оценки производительности модели после завершения обучения. Эти данные никогда не видели модель во время обучения.
Собственный датасет — это просто набор данных, который собирают буквально - ручками. Нужно понять задачу и собрать данные - из открытых источников, API, по сайтам.
Одной цифры нет: зависит от сложности задачи, числа признаков и шума. Практические ориентиры — не меньше сотен размеченных примеров на класс для простой классификации; для регрессии на таблицах — тысячи строк как старт (пример Melbourne Housing). Подробнее о split и k-fold — Разбиение данных. Больше данных помогает только если они релевантны задаче; лишние столбцы и шум ухудшают модель. При нехватке данных — проще алгоритм, регуляризация или transfer learning.
Популярные датасеты
Существует множество стандартных датасетов, используемых для обучения и сравнения моделей:
MNIST — набор из 70 000 изображений рукописных цифр (0-9), каждый размером 28×28 пикселей. Используется для задач классификации изображений.
CIFAR-10 — набор из 60 000 цветных изображений размером 32×32 пикселя, разделенных на 10 классов (самолеты, автомобили, птицы, кошки, олени, собаки, лягушки, лошади, корабли, грузовики).
ImageNet — масштабный датасет с более чем 14 миллионами изображений, размеченных по 20 000 категориям. Используется для задач компьютерного зрения.
IMDb Reviews — набор из 50 000 отзывов на фильмы с двоичной разметкой тональности (положительная или отрицательная).
Wikipedia Text Corpus — большая коллекция текстов из Википедии, используемая для обучения языковых моделей.
Алгоритмы машинного обучения
Линейные модели
Линейная регрессия
Линейная регрессия — это простейший алгоритм машинного обучения, который моделирует линейную зависимость между входными признаками и выходной переменной. Модель представляет собой прямую линию (в случае одного признака) или гиперплоскость (в случае множества признаков).
Код ITЗагрузка примера кода…
// Пример линейной регрессии на C# с использованием ML.NET
using Microsoft.ML;
using Microsoft.ML.Data;
var mlContext = new MLContext();
var data = mlContext.Data.LoadFromTextFile<HouseData>("houses.csv", separatorChar: ',');
var pipeline = mlContext.Transforms.Concatenate("Features", "Size", "Rooms")
.Append(mlContext.Regression.Trainers.Sdca());
var model = pipeline.Fit(data);
// Пример линейной регрессии на Java с использованием Weka
import weka.classifiers.functions.LinearRegression;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
DataSource source = new DataSource("houses.arff");
Instances data = source.getDataSet();
data.setClassIndex(data.numAttributes() - 1);
LinearRegression model = new LinearRegression();
model.buildClassifier(data);
Линейная регрессия используется для задач предсказания числовых значений, таких как прогнозирование цен, температуры или спроса на продукцию.
Логистическая регрессия
Логистическая регрессия — это алгоритм классификации, который предсказывает вероятность принадлежности объекта к определенному классу. Несмотря на название, это метод классификации, а не регрессии.
Код ITЗагрузка примера кода…
// Логистическая регрессия на C# с ML.NET
var mlContext = new MLContext();
var data = mlContext.Data.LoadFromTextFile<IrisData>("iris.csv", separatorChar: ',');
var pipeline = mlContext.Transforms.Concatenate("Features", "SepalLength", "SepalWidth", "PetalLength", "PetalWidth")
.Append(mlContext.BinaryClassification.Trainers.SdcaLogisticRegression());
var model = pipeline.Fit(data);
Логистическая регрессия применяется для бинарной классификации (два класса) и многоклассовой классификации.
Деревья решений и ансамбли
Дерево решений
Дерево решений — это алгоритм, который строит древовидную структуру для принятия решений. Каждый узел дерева представляет собой вопрос о значении признака, а каждая ветвь — возможный ответ на этот вопрос. Как дерево выбирает первый split (энтропия, бэггинг, бустинг) — Деревья решений с нуля.
Код ITЗагрузка примера кода…
// Дерево решений на C# с ML.NET
var mlContext = new MLContext();
var data = mlContext.Data.LoadFromTextFile<CancerData>("cancer.csv", separatorChar: ',');
var pipeline = mlContext.Transforms.Concatenate("Features", "Feature1", "Feature2", "Feature3")
.Append(mlContext.BinaryClassification.Trainers.LightGbm());
var model = pipeline.Fit(data);
Деревья решений интуитивно понятны и легко интерпретируемы. Они работают с числовыми и категориальными данными без необходимости предварительной нормализации.
Случайный лес
Случайный лес — это ансамблевый метод, который объединяет множество деревьев решений для улучшения точности и уменьшения переобучения. Каждое дерево обучается на случайной подвыборке данных, а финальное предсказание формируется путем голосования всех деревьев.
Код ITЗагрузка примера кода…
// Случайный лес на Java с использованием Smile
import smile.classification.RandomForest;
import smile.Data.DataFrame;
import smile.io.Read;
DataFrame data = Read.csv("wine.csv");
RandomForest model = RandomForest.fit(data.x(), data.factor("target").array(), 100);
Случайный лес обладает высокой точностью, устойчив к переобучению и хорошо работает с большими наборами данных.
Методы опорных векторов
SVM (Support Vector Machine)
Метод опорных векторов — это алгоритм, который находит оптимальную гиперплоскость для разделения данных разных классов. SVM стремится максимизировать расстояние (зазор) между ближайшими точками разных классов.
Код ITЗагрузка примера кода…
// SVM на C# с Accord.NET
using Accord.MachineLearning.VectorMachines;
using Accord.MachineLearning.VectorMachines.Learning;
using Accord.Statistics.Kernels;
var teacher = new SequentialMinimalOptimization<Gaussian>()
{
Complexity = 10
};
var svm = teacher.Learn(inputs, outputs);
SVM эффективен для задач с четким разделением классов и работает хорошо даже в пространствах высокой размерности.
Глубокое обучение
Что такое глубокое обучение?
Глубокое обучение — это подраздел машинного обучения, основанный на использовании нейронных сетей с множеством скрытых слоев. Эти сети способны автоматически извлекать иерархические признаки из сырых данных, что делает их особенно мощными для работы со сложными неструктурированными данными.
Глубокое обучение отличается от традиционного машинного обучения тем, что не требует ручного извлечения признаков. Сеть самостоятельно учится выделять важные характеристики на каждом уровне абстракции.
Глубокое обучение используется в CNN, RNN, LSTM и трансформерах. Требует мощных вычислительных ресурсов (например, GPU или TPU).
Нейронные сети
Структура нейронной сети
Нейронная сеть — это вычислительная модель, вдохновленная биологическими нейронными сетями мозга. Сеть состоит из слоев искусственных нейронов, каждый из которых выполняет простые вычисления и передает результат следующему слою.
Основные компоненты нейронной сети:
Входной слой — принимает исходные данные и передает их в сеть. Количество нейронов соответствует количеству входных признаков.
Скрытые слои — промежуточные слои, которые извлекают признаки из данных. Каждый скрытый слой преобразует представление данных на более высокий уровень абстракции.
Выходной слой — формирует окончательный результат работы сети. Количество нейронов зависит от типа задачи (один нейрон для регрессии, несколько для классификации).
Веса — параметры, которые определяют силу связи между нейронами. В процессе обучения веса корректируются для минимизации ошибки.
Функции активации — нелинейные функции, применяемые к выходу каждого нейрона. Они позволяют сети моделировать сложные нелинейные зависимости.
Многослойный перцептрон
Многослойный перцептрон — это простейшая форма нейронной сети с полносвязными слоями. Каждый нейрон в слое соединен со всеми нейронами предыдущего и следующего слоев.
Код ITЗагрузка примера кода…
Код ITЗагрузка примера кода…
Код ITЗагрузка примера кода…
Многослойный перцептрон универсален и может решать широкий спектр задач, от классификации до регрессии.
Сверточные нейронные сети
Что такое CNN?
Сверточная нейронная сеть — это специализированный тип нейронной сети, разработанный для обработки данных с сетчатой топологией, таких как изображения. Сверточные сети используют локальные receptive fields и веса, совместно используемые между нейронами, что делает их эффективными для работы с изображениями.
Архитектура CNN включает следующие типы слоев:
Сверточные слои — применяют фильтры (ядра) к входным данным для выделения признаков. Каждый фильтр обнаруживает определенный паттерн, такой как края, текстуры или формы.
Пулинговые слои — уменьшают пространственную размерность данных, сохраняя наиболее важную информацию. Наиболее распространенный тип — максимальный пулинг, который выбирает максимальное значение в каждом окне.
Полносвязные слои — используются в конце сети для классификации признаков, извлеченных сверточными слоями.
Пример сверточной сети
Код ITЗагрузка примера кода…
// CNN на C# с TensorFlow.NET
var model = keras.Sequential(new Layer[] {
keras.layers.Conv2D(32, 3, activation: "relu", input_shape: new int[] { 28, 28, 1 }),
keras.layers.MaxPooling2D(2, 2),
keras.layers.Conv2D(64, 3, activation: "relu"),
keras.layers.MaxPooling2D(2, 2),
keras.layers.Flatten(),
keras.layers.Dense(128, activation: "relu"),
keras.layers.Dense(10, activation: "softmax")
});
Сверточные нейронные сети доминируют в задачах компьютерного зрения, таких как распознавание изображений, обнаружение объектов и сегментация.
Рекуррентные нейронные сети
Что такое RNN?
Рекуррентная нейронная сеть — это тип нейронной сети, предназначенная для обработки последовательных данных, таких как текст, речь или временные ряды. В отличие от обычных сетей, RNN имеет внутреннюю память, которая позволяет учитывать контекст предыдущих элементов последовательности.
Ключевая особенность RNN — циклические связи, которые передают информацию из предыдущего шага времени на текущий. Это позволяет сети запоминать зависимости на разных временных масштабах.
LSTM и GRU
LSTM (Long Short-Term Memory) — это усовершенствованный вариант рекуррентной сети, разработанный для решения проблемы затухающего градиента. LSTM использует специальные вентили (гейты) для контроля потока информации, что позволяет запоминать долгосрочные зависимости.
GRU (Gated Recurrent Unit) — это упрощенная версия LSTM с меньшим количеством параметров. GRU объединяет некоторые вентили LSTM, сохраняя при этом способность моделировать долгосрочные зависимости.
Код ITЗагрузка примера кода…
# Модель с GRU
model_gru = Sequential([
Embedding(max_features, 128, input_length=maxlen),
GRU(64, dropout=0.2, recurrent_dropout=0.2),
Dense(1, activation='sigmoid')
])
Рекуррентные сети используются для задач обработки естественного языка, прогнозирования временных рядов и генерации последовательностей.
Процесс обучения моделей
Подготовка данных
Предобработка данных
Предобработка данных — это этап подготовки сырых данных для обучения модели. Этот процесс включает очистку, нормализацию и преобразование данных в формат, подходящий для алгоритмов машинного обучения.
Основные шаги предобработки:
Очистка данных — удаление или исправление некорректных, неполных или дублирующихся записей. Обработка пропущенных значений путем удаления строк, заполнения средними значениями или интерполяции.
Нормализация — приведение числовых признаков к единому масштабу. Обычно используется минимаксная нормализация (приведение к диапазону [0, 1]) или стандартизация (приведение к нулевому среднему и единичной дисперсии).
Кодирование категориальных признаков — преобразование категориальных переменных (цвет, размер, тип и т.д.) в числовой формат, который принимают алгоритмы. Базовые приёмы — one-hot, dummy, label, ordinal, count и binary encoding; когда какой выбирать и чем они отличаются — в отдельной статье Кодирование категориальных признаков.
Код ITЗагрузка примера кода…
Обучение модели
Функция потерь
Функция потерь — это метрика, которая измеряет, насколько хорошо модель предсказывает целевые значения. Функция потерь количественно оценивает ошибку модели и служит ориентиром для процесса оптимизации.
Типы функций потерь:
Среднеквадратичная ошибка — используется для задач регрессии. Вычисляет среднее квадратов разностей между предсказанными и фактическими значениями.
Кросс-энтропия — используется для задач классификации. Измеряет различие между предсказанным распределением вероятностей и истинным распределением.
Hinge loss — используется для методов опорных векторов. Штрафует предсказания, которые находятся слишком близко к границе разделения классов.
Оптимизация
Оптимизация — это процесс настройки параметров модели для минимизации функции потерь. Оптимизаторы используют градиенты функции потерь для обновления весов модели в направлении, уменьшающем ошибку.
Популярные алгоритмы оптимизации:
Стохастический градиентный спуск — базовый метод оптимизации, который обновляет веса на основе градиента, вычисленного для одного или нескольких примеров.
Adam — адаптивный метод оптимизации, который комбинирует преимущества методов моментума и адаптивного обучения. Adam автоматически регулирует скорость обучения для каждого параметра.
RMSprop — метод, который адаптирует скорость обучения на основе среднего квадрата градиентов. Эффективен для нестационарных целевых функций.
from tensorflow.keras.optimizers import SGD, Adam, RMSprop
# SGD с моментумом
sgd_optimizer = SGD(learning_rate=0.01, momentum=0.9)
# Adam optimizer
adam_optimizer = Adam(learning_rate=0.001, beta_1=0.9, beta_2=0.999)
# RMSprop optimizer
rmsprop_optimizer = RMSprop(learning_rate=0.001, rho=0.9)
Обратное распространение ошибки
Обратное распространение ошибки — это алгоритм вычисления градиентов функции потерь по параметрам модели. Алгоритм использует цепное правило дифференцирования для эффективного вычисления градиентов в нейронных сетях.
Процесс обратного распространения:
- Вычисляется прямое распространение сигнала через сеть
- Вычисляется функция потерь на выходе сети
- Градиенты распространяются обратно через сеть от выходного слоя к входному
- Веса обновляются на основе вычисленных градиентов
Регуляризация и предотвращение переобучения
Переобучение и недообучение
Переобучение — это ситуация, когда модель слишком хорошо подстраивается под обучающие данные, включая шум и случайные флуктуации. Переобученная модель показывает высокую точность на обучающем наборе, но плохую обобщающую способность на новых данных.
Недообучение — это ситуация, когда модель недостаточно сложна для захвата основных паттернов в данных. Недообученная модель показывает низкую точность как на обучающем, так и на тестовом наборе.
Интуиция смещения и дисперсии (bias–variance) для новичков — в отдельной статье Смещение, дисперсия и переобучение.
Методы регуляризации
Регуляризация — это набор техник, предназначенных для предотвращения переобучения модели. Регуляризация добавляет штрафы к функции потерь или изменяет архитектуру модели для улучшения обобщающей способности.
L1 и L2 регуляризация — добавляют штрафы к функции потерь на основе абсолютных значений (L1) или квадратов (L2) весов модели. L1 регуляризация способствует разреженности весов, L2 регуляризация уменьшает общую величину весов.
Dropout — случайно отключает часть нейронов во время обучения для предотвращения чрезмерной зависимости от отдельных нейронов. Это заставляет сеть учиться более надежным представлениям.
Ранняя остановка — прекращает обучение, когда производительность на валидационном наборе перестает улучшаться. Это предотвращает дальнейшее подстраивание под обучающие данные.
from tensorflow.keras.layers import Dropout
from tensorflow.keras import regularizers
# Модель с регуляризацией
model = Sequential([
Dense(128, activation='relu', kernel_regularizer=regularizers.l2(0.01), input_shape=(100,)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=regularizers.l2(0.01)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
Оценка моделей
Метрики качества
Для задач классификации
Accuracy (доля верных ответов) — доля правильно классифицированных объектов от общего количества. Простая и интуитивно понятная метрика, но может быть вводящей в заблуждение при несбалансированных классах.
Precision (точность предсказания положительного класса) — доля истинно положительных предсказаний от всех предсказанных положительных. Показывает, насколько можно доверять положительному предсказанию модели.
Recall (полнота) — доля истинно положительных предсказаний от всех фактически положительных объектов. Показывает, насколько хорошо модель находит все положительные случаи.
F1-мера — гармоническое среднее точности и полноты. Используется, когда необходимо сбалансировать точность и полноту.
ROC-AUC — площадь под кривой ошибок. Измеряет способность модели различать классы независимо от выбранного порога классификации.
Код ITЗагрузка примера кода…
Для задач регрессии
Среднеквадратичная ошибка — среднее квадратов разностей между предсказанными и фактическими значениями. Чувствительна к выбросам.
Средняя абсолютная ошибка — среднее абсолютных разностей между предсказанными и фактическими значениями. Менее чувствительна к выбросам, чем MSE.
Коэффициент детерминации — доля дисперсии зависимой переменной, объясняемая моделью. Значения близкие к 1 указывают на хорошее качество модели.
Код ITЗагрузка примера кода…
Кросс-валидация
Кросс-валидация — это метод оценки модели, при котором данные разделяются на несколько частей (фолдов). Модель обучается на одной части данных и тестируется на другой, и этот процесс повторяется для каждого фолда.
K-fold кросс-валидация — наиболее распространенный метод, при котором данные разделяются на K равных частей. Модель обучается K раз, каждый раз используя K-1 фолдов для обучения и 1 фолд для тестирования. Подробнее о leakage, stratify и validation vs test — Разбиение данных.
Код ITЗагрузка примера кода…
Кросс-валидация предоставляет более надежную оценку модели, особенно при ограниченном количестве данных.
Инструменты и экосистема
Библиотеки для машинного обучения
Scikit-learn
Scikit-learn — это библиотека машинного обучения на Python, предоставляющая простые и эффективные инструменты для анализа данных и построения моделей. Scikit-learn включает широкий спектр алгоритмов классификации, регрессии, кластеризации и предобработки данных.
Пошаговый маршрут по регрессии, классификации, Pipeline и GridSearchCV — в статье Scikit-learn — регрессия и классификация.
Код ITЗагрузка примера кода…
TensorFlow и Keras
TensorFlow — это платформа для глубокого обучения с открытым исходным кодом, разработанная Google. TensorFlow предоставляет гибкие инструменты для построения и обучения нейронных сетей различной сложности.
Keras — это высокоуровневый API для построения нейронных сетей, работающий поверх TensorFlow. Keras упрощает создание и обучение моделей глубокого обучения.
Компактный маршрут — Sequential, MNIST, callbacks, сохранение модели — в Keras и TensorFlow — нейросети.
Код ITЗагрузка примера кода…
PyTorch
PyTorch — библиотека глубокого обучения с динамическими вычислительными графами; популярна в исследованиях и среди LLM/CV-команд. Установка, тензоры, autograd, Dataset, цикл обучения и сквозной пайплайн — в отдельной статье PyTorch для разработчика.
Библиотеки для обработки данных
Pandas
Pandas — это библиотека для анализа и обработки данных на Python. Pandas предоставляет мощные структуры данных и инструменты для манипулирования табличными данными.
Код ITЗагрузка примера кода…
NumPy
ИИ и машинное обучение пишут на Java, C++, Go, JavaScript, R и других языках. Python стал стандартом де-факто из‑за простого синтаксиса и экосистемы — NumPy, pandas, scikit-learn, PyTorch, TensorFlow. Ограничение "только Python" — миф; ограничение "нужны библиотеки для матриц и автоматического дифференцирования" — реальность.
NumPy — фундаментальная библиотека для научных вычислений на Python. Она даёт многомерные массивы и матрицы, векторизованные операции и готовые математические функции — без ручной записи циклов для каждого умножения в нейросети. Базовые массивы и матрицы — NumPy — массивы и матрицы; минимальный пример обучения одного нейрона — в статье Первое обучение: перцептрон на NumPy.
Код ITЗагрузка примера кода…
Визуализация данных
Matplotlib
Matplotlib — это библиотека для создания статических, анимированных и интерактивных визуализаций на Python. Matplotlib предоставляет гибкие инструменты для построения различных типов графиков.
Код ITЗагрузка примера кода…
Seaborn
Seaborn — это библиотека для статистической визуализации данных, построенная поверх Matplotlib. Seaborn предоставляет высокоуровневый интерфейс для создания привлекательных и информативных статистических графиков.
Код ITЗагрузка примера кода…
Практические примеры
Пример 1 — Классификация изображений с помощью CNN
Код ITЗагрузка примера кода…
Пример 2 — Анализ тональности текста с помощью LSTM
Код ITЗагрузка примера кода…
Пример 3 — Прогнозирование временных рядов
Код ITЗагрузка примера кода…
Пример 4 — Кластеризация без учителя
Код ITЗагрузка примера кода…