JVM, память и потоки
JVM, память и потоки
Как читать эту главу
Глава длинная — это нормально для JVM. Идите слоями:
- Сейчас — что такое JVM, JDK, JIT, области памяти, потоки, GC (ниже по тексту).
- После первой программы — вернитесь к разделу про сборку мусора и демо
<ExternalPlayEmbed example="code-dev/garbage-collector-demo" title="Сборщик мусора" minHeight={480} />. - Перед продом — команды
jcmd, heap dump, JFR в JVM в проде; флаги-Xmx,-XX:+UseG1GC, лог GC — справочник, §24.
Если термин "байт-код" пока абстрактен — сначала основы Java и запуск Main в IDE: вы уже запускали JVM, просто не называли её по имени.
JVM
★ JVM – виртуальная машина, которая загружает, интерпретирует и выполняет байт-код. Она обеспечивает платформенную независимость. Разные ОС имеют разные реализации JVM, но байт-код остаётся одинаковым.
Для практики это означает: один и тот же .jar можно запускать в разных средах, если там совместимая версия JDK. Поэтому в проектах всегда фиксируют целевую версию Java и проверяют её в CI.
Цепочка от .java через javac и артефакты до Class Loader, Verifier и JIT — в Основы языка Java. В этой главе — устройство JVM после загрузки классов — реализации, память, сборка мусора, потоки, диагностика.
Различные организации создают собственные реализации виртуальной машины Java, соответствующие спецификации Java Virtual Machine Specification. Основные реализации:
HotSpot — стандартная реализация от Oracle, входит в состав официального JDK. Использует адаптивную оптимизацию через JIT-компиляторы C1 (client) и C2 (server). Применяется в большинстве enterprise-приложений.
OpenJ9 — разработка компании IBM, теперь часть проекта Eclipse Foundation. Отличается низким потреблением памяти и быстрым запуском. Часто используется в облачных средах и микросервисах.
GraalVM — многоязычная виртуальная машина от Oracle Labs. Поддерживает выполнение не только Java, но и JavaScript, Python, Ruby, R, а также нативную компиляцию приложений через Native Image. Позволяет создавать standalone-исполняемые файлы без необходимости установки JVM.
Microsoft Build of OpenJDK — официальная сборка от Microsoft, оптимизированная для работы в Azure и Windows-средах. Включает поддержку современных процессорных архитектур.
Amazon Corretto — бесплатная реализация от Amazon с долгосрочной поддержкой. Оптимизирована для работы в AWS, включает патчи для повышения производительности в облачных сценариях.
Zing — коммерческая JVM от Azul Systems. Предоставляет предсказуемую задержку сборки мусора даже при работе с кучами размером в сотни гигабайт. Применяется в финансовых системах и приложениях реального времени.
Dragonwell — реализация от Alibaba, ориентированная на работу в крупных распределённых системах. Включает улучшенные алгоритмы сборки мусора и инструменты профилирования.
Axiom JDK
Axiom JDK — российская тиражируемая сборка JDK (Java Development Kit, набор для разработки и запуска Java). Слово "тиражируемая" означает, что вендор поставляет готовые дистрибутивы с регламентом обновлений, тестирования и поддержки, а команда получает одну и ту же платформу на рабочих местах, в CI и на серверах.
Сборка опирается на OpenJDK — открытую реализацию Java. Байт-код, .jar, Maven/Gradle и Spring-приложения ведут себя так же, как на другой JDK той же версии языка. Меняется поставка, сопровождение и инфраструктура обновлений, а не синтаксис Java.
Axiom JDK часто ставят вместе с российской IDE OpenIDE, где JDK можно скачать и переключать прямо из среды разработки.
| Термин | Коротко |
|---|---|
| JDK | Компилятор javac, java, стандартные библиотеки и JVM в одном дистрибутиве |
| JVM | Виртуальная машина, которая исполняет байт-код (см. начало этой главы) |
| OpenJDK | Открытый эталон экосистемы Java; на нём строятся Corretto, Microsoft Build of OpenJDK и Axiom JDK |
| Импортозамещение | Переход на ПО из реестра отечественного ПО и локальных вендоров при сохранении совместимости стека |
Когда берут в проект
- единый JDK у разработчиков, в пайплайне сборки и на продакшене;
- требования к российскому ПО в госсекторе и крупном корпоративном контуре;
- связка с Spring Framework и BPM-стеком (OpenBPM Engine).
Ссылки
- axiomjdk.ru — дистрибутивы, документация, линейка Certified/Pro;
- openide.ru и обзор OpenIDE;
- JDK в глоссарии.
JIT (Just-In-Time) компилятор — это компонент JVM, который компилирует байт-код в машинный код непосредственно во время выполнения программы, а не до старта приложения. Его задача — улучшить производительность, оптимизируя код, исходя из реальных условий работы программы.
JIT компилирует только те части кода, которые реально исполняются, и может применять различные оптимизации для ускорения работы приложения.
Это позволяет сочетать гибкость интерпретируемого байт-кода и производительность нативного кода.
JIT-компилятор преобразует байт-код в машинный код во время выполнения программы. Процесс происходит поэтапно:
- Классы загружаются в память, байт-код интерпретируется.
- JVM отслеживает частоту вызова методов через счётчики профилирования.
- Методы, вызываемые часто (горячие методы), передаются компилятору уровня C1 для быстрой компиляции с минимальными оптимизациями.
- Наиболее критичные участки кода передаются компилятору уровня C2 для глубокой оптимизации — инлайнинг, удаление мёртвого кода, оптимизация циклов.
- Скомпилированный машинный код заменяет интерпретируемый байт-код в области кода (Code Cache).
- При изменении поведения программы (например, новая ветка выполнения) JVM может выполнить деоптимизацию и вернуться к интерпретации.
Пример профилирования в коде:
Код ITЗагрузка примера кода…
Разбор:
mainзапускает два цикла с одинаковым методомcalculate, чтобы JVM успела собрать статистику по "горячему" коду.- На первых итерациях метод обычно интерпретируется, а при достижении порога вызовов JIT компилирует его в машинный код.
- Функция
calculate(int x)специально простая и детерминированная, поэтому JIT может эффективно применить инлайнинг и арифметические оптимизации. - Этот пример иллюстрирует ключевую идею JIT: оптимизация принимается на основе реального поведения программы во время выполнения.
Для наблюдения за работой JIT используйте флаги:
-XX:+PrintCompilation // вывод компиляции методов
-XX:+UnlockDiagnosticVMOptions -XX:+LogCompilation
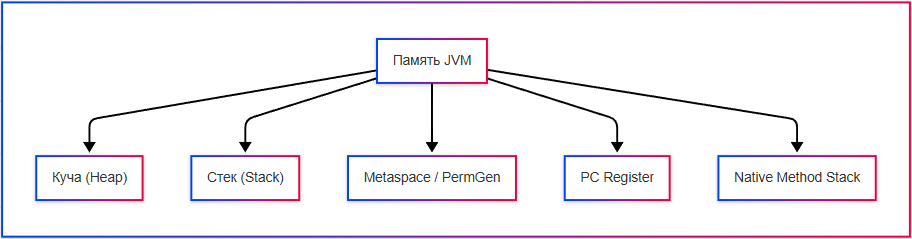
JVM делит память на несколько логических частей (областей):
- Куча (Heap) – хранение объектов Java;
- Стек (Stack) – хранение локальных переменных и вызовов методов;
- Metaspace / PermGen – хранение метаданных классов, методов, полей;
- PC Register – указывает текущую выполняемую инструкцию для каждого потока;
- Native Method Stack – для выполнения native-методов (например, C/C++).
Program Counter Register хранит адрес следующей инструкции байт-кода для выполнения в каждом потоке. Для нативных методов значение регистра не определено. PC Register — самая маленькая область памяти JVM, создаётся автоматически при старте потока.
Пример наблюдения за выполнением:
public class PCRegisterExample {
public static void main(String[] args) {
int a = 10; // инструкция 1: загрузка константы
int b = 20; // инструкция 2: загрузка константы
int c = a + b; // инструкции 3-5: сложение и сохранение
System.out.println(c);
}
}
Разбор:
- Локальные переменные
a,b,cсоздают последовательность байткод-инструкций, которую удобно сопоставлять с работойPC Register. - Выражение
int c = a + b;раскладывается на несколько шагов: загрузка значений, арифметическая операция и запись результата. System.out.println(c)добавляет вызов метода, что позволяет увидеть переходы между инструкциями и управление потоком выполнения.- В связке с
javap -cфрагмент наглядно показывает, как исходный Java-код превращается в исполняемые байткод-команды JVM.
Для просмотра байт-кода используйте javap -c PCRegisterExample.class. Каждая строка вывода соответствует значению PC Register на момент выполнения инструкции.
Native Method Stack обслуживает выполнение методов, написанных на языках низкого уровня (C, C++), вызываемых через JNI (Java Native Interface). Имеет собственную структуру, отличную от Java-стека, и управляется операционной системой.
Пример вызова нативного метода:
Код ITЗагрузка примера кода…
Соответствующий C-код:
#include <jni.h>
#include "NativeExample.h"
JNIEXPORT jint JNICALL Java_NativeExample_computeNative
(JNIEnv *env, jobject obj, jint x, jint y) {
return x * y + 10;
}
Куча
Интерактивная модель — фазы mark-and-sweep и достижимость объектов (языконезависимо). Подробнее: автоматическое управление памятью; сравнение Java, Python и Go — шпаргалка GC.
Play ITЗагрузка интерактивного демо…
★ Куча – это основная область памяти для хранения объектов. Управление памятью здесь осуществляется сборщиком мусора (Garbage Collector). Куча разделена на поколения на основе гипотезы о том, что большинство объектов живут недолго.
Все объекты, созданные оператором new, размещаются в куче. Размер кучи задаётся параметрами -Xms (начальный) и -Xmx (максимальный).
Куча делится на:
- Young Generation (Eden, Survivor);
- Old Generation.
Young Generation состоит из трёх областей:
- Eden — место рождения новых объектов. При заполнении запускается Minor GC.
- Survivor Space (S0 и S1) — два пространства, используемые поочерёдно. Объекты, выжившие после Minor GC, перемещаются из Eden в одно из Survivor-пространств. При следующей сборке выжившие объекты перемещаются в другое Survivor-пространство. Возраст объекта увеличивается с каждым циклом.
Пример распределения в молодом поколении:
Код ITЗагрузка примера кода…
Наблюдение за сборкой мусора:
java -XX:+PrintGCDetails YoungGenExample
[GC (Allocation Failure) [PSYoungGen: 51200K->1024K(56320K)] 51200K->41024K(128000K), 0.0051234 secs]
[GC (Allocation Failure) [PSYoungGen: 52224K->1024K(56320K)] 92048K->91136K(128000K), 0.0062345 secs]
[Full GC (Ergonomics) [PSYoungGen: 1024K->0K(56320K)] [ParOldGen: 91136K->82944K(87040K)] 92160K->82944K(143360K), 0.0523456 secs]
Old Generation (Tenured Generation) хранит долгоживущие объекты, пережившие несколько циклов сборки в молодом поколении. Сборка мусора здесь (Major GC или Full GC) происходит реже, но требует больше времени и останавливает все потоки приложения (stop-the-world pause).
Пример долгоживущих объектов:
Код ITЗагрузка примера кода…
Настройка размеров поколений:
-XX:NewRatio=2 // Old:Young = 2:1
-XX:SurvivorRatio=8 // Eden:Survivor = 8:1 (каждый Survivor 1/10 Young)
-Xmn512m // фиксированный размер Young Generation
Пример распределения объектов:
Код ITЗагрузка примера кода…
Проверка использования памяти:
Код ITЗагрузка примера кода…
У каждого потока есть свой собственный стек фиксированного размера (по умолчанию 1 МБ на платформе x64). Стек содержит локальные переменные и вызовы методов (в виде фреймов). После выхода из метода стек автоматически очищается. К примеру, создавая метод и переменную внутри метода, переменная будет храниться в стеке.
Пример работы стека:
Код ITЗагрузка примера кода…
Разбор:
- В
mainв стек-фрейме хранятся примитивxи ссылки на объекты, а сами объекты размещаются в куче. - Вызов
compute(5, 3)создаёт новый фрейм стека, где размещаются параметрыa,bи локальная переменнаяresult. - Внутренний вызов
add(result, 10)добавляет ещё один фрейм поверх предыдущего, демонстрируя принцип LIFO для стека вызовов. - После
returnфреймы удаляются в обратном порядке, поэтому память локальных переменных освобождается автоматически без участия GC.
Переполнение стека при глубокой рекурсии:
public class StackOverflow {
public static void main(String[] args) {
recurse(0);
}
static void recurse(int depth) {
System.out.println("Глубина: " + depth);
recurse(depth + 1); // бесконечная рекурсия → StackOverflowError
}
}
Для увеличения размера стека используйте флаг -Xss2m (2 МБ на поток).
Пул строк
Пул строк — это специальная область памяти в heap, где хранятся уникальные строковые литералы. При создании строки через String s = "hello", JVM проверяет, есть ли уже такая строка в пуле. Если есть, то возвращается ссылка на существующий объект, если нет, то создаётся новый и добавляется в пул.
Это экономит память и ускоряет сравнение строк с помощью ==, так как строки из пула имеют одинаковую ссылку. Для добавления строки в пул вручную используют метод intern().
Пример работы пула строк:
Код ITЗагрузка примера кода…
Вывод размера пула строк:
Код ITЗагрузка примера кода…
Metaspace
★ Metaspace заменил PermGen в Java 8+. Хранит описание классов, статические данные и методы. Располагается в native-памяти, а не в куче. В отличие от PermGen, Metaspace может динамически расширяться. Автоматически расширяется при загрузке новых классов.
Пример загрузки классов:
Код ITЗагрузка примера кода…
Мониторинг использования Metaspace:
Код ITЗагрузка примера кода…
Ограничение размера Metaspace: -XX:MaxMetaspaceSize=256m
PermGen (Permanent Generation) использовалась в Java 7 и ранее для хранения метаданных классов, пула строк и статических переменных. Располагалась внутри кучи Java, имела фиксированный размер (-XX:MaxPermSize), что приводило к ошибкам java.lang.OutOfMemoryError: PermGen space при динамической загрузке классов.
Пример проблемы в Java 7:
// В среде с ограниченным PermGen (Java 7)
public class PermGenLeak {
public static void main(String[] args) throws Exception {
while (true) {
// Загрузка нового класса в каждом цикле
ClassLoader loader = new URLClassLoader(new URL[]{new File("classes").toURI().toURL()});
Class<?> clazz = loader.loadClass("com.example.DynamicClass");
// loader не удаляется → утечка в PermGen
}
}
}
В Java 8 PermGen полностью заменён на Metaspace, размещённый в native-памяти с динамическим расширением.
Сборщик мусора
Java автоматически управляет выделением и освобождением памяти через сборщик мусора (Garbage Collector). Когда объект становится недостижим (нет ссылок на него), он помечается как "мусор". И GC периодически освобождает память.
GC снижает риск ручных ошибок управления памятью, но не отменяет архитектурные проблемы. Долгоживущие ссылки, большие кэши без лимитов и чрезмерное создание временных объектов всё равно приводят к деградации производительности.
Достижимость определяется наличием цепочки ссылок от GC roots (активные стеки потоков, статические поля, локальные переменные).
Сборщики и регионы G1
| Сборщик | Кратко |
|---|---|
| Serial | Один поток, STW — малые приложения |
| Parallel | Несколько потоков — упор на throughput |
| G1 | Регионы E/S/O, приоритет "мусорных" регионов — дефолт с JDK 9 |
| ZGC / Shenandoah | Низкие паузы на больших heap |
В G1 куча — набор регионов (~1–32 МБ) — E (Eden), S (Survivor), O (Old). Параметры -XX:+UseG1GC, -XX:MaxGCPauseMillis, лог -Xlog:gc* — в сравнении GC и настройке JVM в разделе 4.15.
Пример цикла жизни объекта:
Код ITЗагрузка примера кода…
Пример утечки памяти через статическую коллекцию:
public class MemoryLeakExample {
// Статическая коллекция удерживает объекты вечно
private static List<byte[]> leak = new ArrayList<>();
public static void main(String[] args) {
while (true) {
leak.add(new byte[1024 * 1024]); // 1 MB
System.out.println("Добавлен объект, всего: " + leak.size());
try { Thread.sleep(100); } catch (InterruptedException e) {}
}
// Приведёт к OutOfMemoryError
}
}
Наблюдение за GC через JMX:
public class GCWatcher {
public static void main(String[] args) {
List<GarbageCollectorMXBean> gcBeans = ManagementFactory.getGarbageCollectorMXBeans();
for (GarbageCollectorMXBean gcBean : gcBeans) {
System.out.println("Сборщик: " + gcBean.getName());
System.out.println("Количество сборок: " + gcBean.getCollectionCount());
System.out.println("Время сборки: " + gcBean.getCollectionTime() + " ms");
}
}
}
Жизненный цикл объекта
Таким образом, объект проходит свой жизненный цикл.
Объект проходит пять этапов:
- Загрузка класса — класс загружается ClassLoader'ом, выделяется место в Metaspace.
- Создание — оператор
newвыделяет память в куче, вызывается конструктор. - Использование — объект доступен через ссылки, вызываются методы.
- Недостижимость — все ссылки на объект удалены или выходят за область видимости.
- Сборка мусора — GC обнаруживает недостижимый объект и освобождает память.
Детальный пример:
Код ITЗагрузка примера кода…
★ Жизненный цикл объекта:
- Создание: new Object();
- Использование: вызов методов, работа с полями;
- Неиспользуемый: нет активных ссылок;
- Кандидат на удаление: GC помечает его;
- Удалён: память освобождается.
Жизненный цикл бина в Spring
В Spring объект становится бином, когда его создаёт и управляет им контейнер ApplicationContext (или BeanFactory), а не ваш прямой вызов new.
Развёрнутая картина Spring-стека, IoC/DI и инфраструктурных модулей — в отдельной статье: Spring Framework.
Что это даёт на практике:
- Spring сам строит граф зависимостей и создаёт объекты в правильном порядке
- служебные механизмы подключаются автоматически, например транзакции и кэширование
- контейнер закрывает ресурсы, поэтому меньше утечек соединений и фоновых задач
Термины, которые нужно знать перед схемой:
- IoC-контейнер — часть Spring, которая хранит и управляет бинами
- DI (
Dependency Injection) — способ передать зависимости объекту извне - post-processor — расширение Spring, которое может изменить бин до и после инициализации
- прокси — обёртка над бином, через которую Spring добавляет дополнительное поведение
Этапы жизненного цикла singleton-бина:
- Создание экземпляра
- Spring вызывает конструктор класса
- Внедрение зависимостей
- контейнер подставляет другие бины и значения конфигурации
- Вызов Aware-интерфейсов
- при реализации
BeanNameAware,BeanFactoryAware,ApplicationContextAwareбин получает доступ к служебному контексту
- при реализации
BeanPostProcessor.postProcessBeforeInitialization- выполняются пользовательские и встроенные обработчики до инициализации
@PostConstruct- метод с этой аннотацией вызывается после внедрения зависимостей
afterPropertiesSet()иinit-method- сначала
InitializingBean.afterPropertiesSet(), потом кастомный метод инициализации
- сначала
BeanPostProcessor.postProcessAfterInitialization- здесь Spring может обернуть бин в прокси для
@Transactional,@Async,@Cacheableи AOP-аспектов
- здесь Spring может обернуть бин в прокси для
- Бин готов к работе
- его можно внедрять в другие компоненты и использовать в коде
Что происходит при остановке приложения:
@PreDestroyDisposableBean.destroy()- кастомный
destroy-method
Минимальный пример декларации init/destroy:
@Bean(initMethod = "init", destroyMethod = "shutdown")
public PaymentService paymentService() {
return new PaymentService();
}
public class PaymentService {
@PostConstruct
public void warmUp() {
// вызывается после внедрения зависимостей
}
public void init() {
// дополнительная инициализация бина
}
@PreDestroy
public void beforeDestroy() {
// освобождение ресурсов перед остановкой контекста
}
public void shutdown() {
// финальное закрытие ресурсов
}
}
Важно:
- Для
prototype-бинов Spring обычно вызывает только этапы создания/инициализации; destroy-колбэки автоматически не вызываются. - Не каждый бин становится прокси, но инфраструктурные аннотации (
@Transactional, аспекты) добавляют этот слой именно после инициализации. - Порядок может расширяться пользовательскими
BeanPostProcessor, но базовая схема выше остаётся опорной. - Быстрый старт по терминам и аннотациям есть в Spring Framework, а практический запуск проекта — в Первая программа на Spring.
Многопоточность
Когда выполняется какое-то действие, оно выполняется в потоке. Java поддерживает многопоточность – способность выполнять несколько потоков одновременно. Это обеспечивает повышение производительности (особенно на многоядерных процессорах), улучшение пользовательского опыта (фоновые задачи), эффективную обработку параллельных задач.
Классический Thread в этой главе — это platform thread (1:1 с потоком ОС).
С Java 21 для массового блокирующего I/O добавлены virtual threads: JVM планирует их поверх небольшого пула carriers, а ядро видит только OS threads.
Подробная схема — Virtual Threads (Java 21+); выбор API — асинхронность.
Как создать поток?
Есть два основных способа – наследование от Thread и реализация Runnable:
- Наследование от Thread:
class MyThread extends Thread {
public void run() {
System.out.println("Поток запущен");
}
}
MyThread t = new MyThread();
t.start(); // запускает новый поток
Код ITЗагрузка примера кода…
- Реализация Runnable:
class MyRunnable implements Runnable {
public void run() {
System.out.println("Поток запущен");
}
}
Thread t = new Thread(new MyRunnable());
t.start();
Код ITЗагрузка примера кода…
Преимущества Runnable:
- Возможность наследования от другого класса
- Разделение логики задачи и механизма выполнения
- Возможность передачи одной задачи нескольким потокам
- Совместимость с пурами потоков (ExecutorService)
Предпочтительнее использовать Runnable, так как это позволяет разделить логику и поток.
Сравнение способов создания потока
| Критерий | Наследование Thread | Реализация Runnable |
|---|---|---|
| Гибкость | Одиночное наследование — класс уже занят | Можно наследовать другой класс |
| Разделение ответственности | Логика потока и задачи в одном классе | Задача отделена от управления потоком |
| Повторное использование | Сложнее | Одну задачу можно запустить в разных потоках |
| Рекомендация | Простые учебные примеры | Предпочтительный вариант в production |
start() и run() — в чём разница
| Аспект | run() | start() |
|---|---|---|
| Создание нового потока | Нет | Да |
| Где выполняется код | В текущем потоке (обычно main) | В новом потоке |
| Параллелизм | Отсутствует | Присутствует |
| Повторный вызов | Допустим | Недопустим (IllegalThreadStateException) |
public class StartVsRun {
public static void main(String[] args) {
Thread thread = new Thread(() ->
System.out.println("Поток: " + Thread.currentThread().getName())
);
System.out.println("=== run() напрямую ===");
thread.run(); // выполнится в main
System.out.println("=== start() ===");
thread.start(); // выполнится в Thread-0
}
}
Вызов run() напрямую не создаёт новый поток — это распространённая ошибка новичков.
Повторный вызов start() на том же объекте Thread приводит к IllegalThreadStateException — поток после завершения находится в состоянии TERMINATED и не перезапускается; нужен новый экземпляр Thread.
Таким образом, благодаря многопоточности, мы можем использовать несколько ядер, а приложения не будут зависать во время долгих операций.
Демон-потоки и Shutdown Hook
Демон-поток (daemon thread)
Поток с флагом daemon = true не удерживает JVM — когда завершаются все non-daemon потоки, виртуальная машина завершает работу, не дожидаясь демонов.
Thread worker = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
// фоновая работа
}
});
worker.setDaemon(true); // до start()
worker.start();
| User thread (обычный) | Daemon thread | |
|---|---|---|
| Завершение JVM | Блокирует выход, пока поток жив | JVM может завершиться без ожидания |
| Типичное применение | Бизнес-логика, HTTP-обработка | Сбор метрик, очистка кэша, мониторинг |
| Установка флага | По умолчанию false | setDaemon(true) до start() |
После start() сменить тип потока на демон нельзя — будет IllegalThreadStateException.
Поток main — обычный (non-daemon). JVM создаёт также служебные демоны (например, сборщик мусора).
Shutdown Hook
Runtime.addShutdownHook(Thread hook) регистрирует код, который JVM выполнит при штатном завершении (Ctrl+C в консоли, System.exit(), остановка контейнера). Это не замена graceful shutdown в сервере, но удобно для закрытия файлов, сброса буферов, остановки пула:
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
System.out.println("Закрываем ресурсы...");
// pool.shutdown(), закрытие соединений
}));
Ограничения:
- хуки не выполняются при
kill -9/ аварийном падении процесса; - хук должен завершиться быстро — иначе JVM может принудительно оборвать завершение;
- не вызывайте из хука сложные операции с теми же ресурсами, что уже закрыты в
main.
Современные приложения чаще используют явный lifecycle (Spring ContextClosedEvent, ExecutorService.shutdown()), но вопрос на собеседовании сводится к механизму JVM.
Жизненный цикл потока
Потоки тоже имеют свой жизненный цикл из состояний:
- New – создан, но ещё не запущен;
- Runnable – готов к выполнению или уже выполняется;
- Blocked / Waiting – ожидает завершения другого потока или блокировки;
- Timed Waiting – ожидает ограниченное время (например, sleep());
- Terminated – завершил работу.
New
Поток создан, но метод start() ещё не вызван.
Thread thread = new Thread(() -> {
System.out.println("Работа потока");
});
// Состояние: NEW
System.out.println(thread.getState()); // NEW
Runnable
Поток запущен (start() вызван) и готов к выполнению. Может выполняться процессором или ожидать своей очереди в планировщике ОС.
Thread thread = new Thread(() -> {
for (int i = 0; i < 1000000; i++) {
// активная работа
}
});
thread.start();
// Состояние: RUNNABLE
System.out.println(thread.getState()); // RUNNABLE
Blocked
Поток ожидает получения монитора для входа в синхронизированный блок или метод.
Код ITЗагрузка примера кода…
Waiting
Поток ожидает неограниченное время: вызов Object.wait(), Thread.join() без таймаута, LockSupport.park().
Код ITЗагрузка примера кода…
Timed Waiting
Поток ожидает ограниченное время: Thread.sleep(), Object.wait(timeout), Thread.join(timeout), LockSupport.parkNanos().
public class TimedWaitingExample {
public static void main(String[] args) throws InterruptedException {
Thread sleeper = new Thread(() -> {
try {
Thread.sleep(5000); // сон на 5 секунд
} catch (InterruptedException e) {}
});
sleeper.start();
Thread.sleep(100);
System.out.println("Состояние: " + sleeper.getState()); // TIMED_WAITING
}
}
Terminated
Поток завершил выполнение метода run() или был прерван.
public class TerminatedExample {
public static void main(String[] args) throws InterruptedException {
Thread finished = new Thread(() -> {
System.out.println("Поток завершает работу");
});
finished.start();
finished.join(); // ожидание завершения
System.out.println("Состояние: " + finished.getState()); // TERMINATED
}
}
Полный пример переходов состояний:
Код ITЗагрузка примера кода…
Гонка данных (race condition)
Гонка данных возникает, когда несколько потоков одновременно читают и изменяют общую переменную. Результат зависит от недетерминированного порядка выполнения.
Операция count++ не атомарна — она состоит из трёх шагов:
- Прочитать текущее значение
count. - Увеличить на 1 в регистре процессора.
- Записать обратно в
count.
Если два потока выполняют шаги одновременно, один инкремент может "потеряться":
Поток A: читает count = 5
Поток B: читает count = 5
Поток A: записывает count = 6
Поток B: записывает count = 6 ← ожидали 7
Код ITЗагрузка примера кода…
При каждом запуске результат может отличаться. Решения — синхронизация (synchronized), атомарные типы (AtomicInteger) или высокоуровневые структуры из java.util.concurrent.
Синхронизация
При работе с общими ресурсами могут возникнуть проблемы: гонки данных, неконсистентность состояния. Решение – синхронизация.
Синхронизированный метод:
public synchronized void increment() {
count++;
}
Код ITЗагрузка примера кода…
Синхронизированный блок:
synchronized (lockObject) {
count++;
}
Код ITЗагрузка примера кода…
Проблема взаимной блокировки (deadlock)
Код ITЗагрузка примера кода…
Решение — всегда захватывать замки в одном порядке.
Синхронизировать можно класс - synchronized(MyClass.class), при этом блокировка класса влияет на все экземпляры этого класса.
А можно объект - synchronized(this).
Важно: Поток — это не процесс. Процесс имеет собственное адресное пространство, тогда как поток делит память с другими потоками. Потоки переключаются быстрее, но поток зависит от процесса.
Lock API поверх synchronized
synchronized обычно достаточно для учебных и большинства рабочих сценариев.
Пакет java.util.concurrent.locks берут, когда нужен более точный контроль блокировок.
| Инструмент | Когда применять | Что получаете |
|---|---|---|
ReentrantLock | Нужна попытка захвата с таймаутом и возможность прервать ожидание | Управление блокировкой через API |
ReadWriteLock | Чтений значительно больше, чем записей | Несколько потоков читают одновременно |
StampedLock | Очень частые чтения и борьба за lock | Оптимистичное чтение с меньшим числом блокировок |
Термины:
- Таймаут захвата — время, после которого поток прекращает ждать lock.
- Прерывание ожидания — поток можно снять с ожидания через
interrupt. - Contention — много потоков пытаются взять один и тот же lock.
Пример ReentrantLock с таймаутом:
Lock lock = new ReentrantLock();
if (lock.tryLock(200, TimeUnit.MILLISECONDS)) {
try {
updateSharedState();
} finally {
lock.unlock();
}
} else {
// fallback: отказ или повтор
}
Практическое правило:
- Сначала пишите версию на
synchronized. - На
Lockпереходите после наблюдаемой проблемы в профиле или thread dump. - Для диагностики используйте JVM в проде — jcmd, дамп памяти и JFR.
Память
JMM
Java Memory Model (JMM) — это набор правил, определённых в спецификации языка Java, которые описывают как потоки видят изменения переменных, сделанные другими потоками, когда изменения в памяти одного потока становятся видимыми другим и в каком порядке операции чтения/записи могут быть переупорядочены (компилятором, JVM, процессором).
Пример нарушения видимости без синхронизации
Код ITЗагрузка примера кода…
Без синхронизации процессор или компилятор могут переупорядочить операции, и читающий поток увидит ready = true, но не увидит обновлённое значение number.
У каждого потока есть своя локальная копия переменных (в кэше CPU или регистрах), все работают напрямую с общей оперативной памятью. Без JMM один поток может изменить переменную, а другой — никогда не увидеть это изменение, потому что читает старое значение из своего кэша. JMM решает эту проблему, давая гарантии согласованности при многопоточной работе.
Без модели памяти программы вели бы себя по-разному на разных платформах (Intel, ARM и т.д.), оптимизации компилятора могли бы сломать логику и невозможно было бы писать надёжные многопоточные приложения. JMM даёт предсказуемость — если правильно использовать synchronized, volatile, final, java.util.concurrent, то программа будет работать одинаково на всех JVM.
Видимость
Видимость (Visibility) подразумевает, что изменение переменной в одном потоке должно становиться видимым другим потокам.
// Без volatile — второй поток может никогда не увидеть изменения!
volatile boolean flag = false;
// Поток 1
flag = true;
// Поток 2
while (!flag) {
// Может выполняться вечно, если нет volatile!
}
volatile гарантирует, что запись в переменную сразу попадает в основную память, а чтение всегда идёт из основной памяти, а не из кэша.
Исправление через volatile
Код ITЗагрузка примера кода…
Упорядоченность
Упорядоченность (Ordering) это следующий аспект JMM. Компилятор и процессор могут переупорядочивать операции для оптимизации. Но JMM говорит: некоторые операции нельзя переставлять без потери корректности. Пример:
int a = 0;
boolean ready = false;
// Поток 1
a = 42; // 1
ready = true; // 2 ← может быть выполнено ДО 1!
// Поток 2
if (ready) {
System.out.println(a); // Может вывести 0 вместо 42!
}
Решение — использовать synchronized, volatile, или happens-before связи.
happens-before - ключевое понятие в JMM. Говорят, что операция A happens-before операции B — значит, A гарантированно видна и упорядочена перед B.
Примеры happens-before:
- Внутри одного потока: код выполняется по порядку.
- При выходе из synchronized блока → все изменения видны тому, кто войдёт в этот блок.
- Запись в volatile переменную happens-before чтения этой переменной.
- Запуск потока: действия в родительском потоке happen-before старту дочернего.
- Завершение потока: его действия happen-before .join() в другом потоке.
Это механизм, который делает многопоточный код предсказуемым.
Happens-before отношения
Встроенные happens-before связи:
Код ITЗагрузка примера кода…
Пример с очередью событий
Код ITЗагрузка примера кода…
Каждая операция notify/notifyAll создаёт happens-before связь с последующим пробуждением через wait, гарантируя видимость всех изменений, сделанных до вызова notify.
Похожий механизм есть в C# - называется он .NET Memory Model, поддерживает volatile, lock, Interlocked, MemoryBarrier. Также есть happens-before -подобные правила.
JMM 4 гарантии которые стоит помнить
Java Memory Model отвечает на два вопроса:
- когда другой поток увидит изменение переменной;
- в каком порядке потоки увидят операции чтения и записи.
Главные гарантии:
- Program order — в одном потоке код выполняется в порядке написания.
- Monitor lock rule — после выхода из
synchronizedизменения видны потоку, который войдет в тот же монитор. - Volatile rule — запись в
volatileвидна при следующем чтении этой же переменной. - Thread lifecycle rules — действия до
start()видны в новом потоке, действия потока видны послеjoin().
Мини-чеклист выбора примитива синхронизации:
| Задача | Обычно брать |
|---|---|
| Флаг остановки/сигнал готовности | volatile |
| Счетчик, инкремент, CAS-операция | AtomicInteger/AtomicLong |
| Несколько связанных полей как одна атомарная операция | synchronized или Lock |
Типичная ошибка новичка:
- поставить
volatileнаcount, где используетсяcount++; - ожидать корректный итог инкрементов;
- получить потерянные обновления.
Причина простая. volatile дает видимость, но выражение count++ состоит из нескольких шагов и не является атомарным.
Подробнее про практические сценарии смотрите в Асинхронность в Java и Справочник по Java.
Практический минимум для production
- Контроль версии JDK и GC в окружении.
- Базовые метрики heap, пауз GC и количества потоков.
- Снимок потока (
jstack) и heap dump при аномалии. - Понимание разницы CPU-bound и wait/block в потоках.
Команды, которые стоит уметь запускать руками:
jcmd <pid> VM.flags
jcmd <pid> GC.heap_info
jcmd <pid> Thread.print
Частые антипаттерны
- "Лечить" гонку данных только
volatile, когда нужна атомарность. - Создавать слишком много короткоживущих потоков вместо пула.
- Игнорировать
InterruptedExceptionи не восстанавливать флаг прерывания. - Синхронизироваться на публичных объектах (
String,ClassLoader, внешние ссылки).
Связанные статьи
- Отладка и пошаговый анализ проблем: Отладка Java-кода в IDE
- Основы синтаксиса и классов: Основные конструкции языка Java
- Работа с данными в памяти приложения: Коллекции в Java
Базовый разбор HTTP и HTTPS находится в отдельной статье — HTTP как основа веб-интеграций.