Kafka
Kafka
Что такое Apache Kafka?
Apache Kafka — это распределённая потоковая платформа (streaming platform), которая предназначена для обработки больших объёмов данных в реальном времени. Kafka часто используется для построения систем, где требуется высокая производительность, масштабируемость и надёжность.
Официальный сайт - https://kafka.apache.org/
Kafka работает в кластере, поддерживает обработку данных в реальном времени и может обрабатывать миллионы сообщений в секунду.
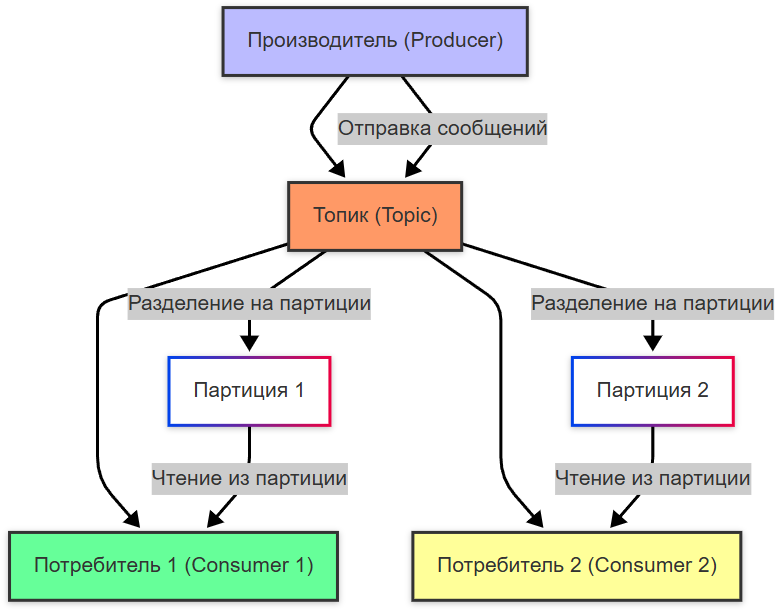
Компоненты
Основные компоненты Kafka:
- Брокер (Broker) — это узел (сервер) в Kafka-кластере, который отвечает за хранение и управление данными. Каждый брокер хранит часть данных (топиков) и обрабатывает запросы от продюсеров и консьюмеров. В кластере может быть несколько брокеров для обеспечения отказоустойчивости и масштабируемости.
- Кластер (Cluster) — это группа брокеров, которые работают вместе для обработки данных. Kafka использует ZooKeeper (или Raft в новых версиях) для координации работы брокеров в кластере.
- Координатор (Coordinator) — это специальный брокер, который отвечает за управление группами консьюмеров. Он отслеживает, какие консьюмеры читают данные из каких партиций, и управляет оффсетами.
- Топик (Topic) — это логический канал, через который передаются сообщения. Каждый топик разделяется на партиции (partitions) для параллельной обработки данных.
- Партиция (Partition) — это упорядоченный лог данных внутри топика. Каждая партиция хранится на одном брокере, но может реплицироваться на другие брокеры для отказоустойчивости. Сообщения в партиции имеют строгий порядок, что позволяет гарантировать последовательность обработки.
- Оффсет (Offset) — это уникальный идентификатор сообщения в партиции. Консьюмеры используют оффсеты для отслеживания своего прогресса при чтении данных. Оффсеты сохраняются либо на стороне консьюмера, либо в Kafka.
- Продюсер (Producer) — это приложение или сервис, которое отправляет сообщения в Kafka. Продюсер выбирает топик и партицию для отправки сообщений.
- Консьюмер (Consumer) — это приложение или сервис, которое читает сообщения из Kafka. Консьюмеры организованы в группы (consumer groups), чтобы распределить нагрузку между несколькими экземплярами.
Kafka использует модель «продюсер-брокер-консьюмер» для обработки данных.
Вот как это работает:
- продюсер отправляет сообщения, пишет их в определённый топик;
- сообщения автоматически распределяются по партициям топика;
- каждый брокер хранит данные в партициях - данные сохраняются в течение заданного времени (например, неделя);
- консьюмер подключается к топику и начинает читать сообщения;
- каждый консьюмер в группе получает данные из одной или нескольких партиций;
- координатор следит за тем, какие консьюмеры читают данные и из каких партиций, если консьюмер выходит из строя, его партиции переназначаются другим консьюмерам.
Архитектура Kafka
Базовые концепции распределённой очереди сообщений
Топики и партиции
Топик (topic) — логический канал для хранения потока сообщений с общим назначением. Физически топик разделён на упорядоченные партиции (partitions), каждая из которых представляет собой неизменяемый упорядоченный журнал записей. Партиции обеспечивают горизонтальное масштабирование: одна партиция обрабатывается одним брокером, но топик может содержать множество партиций, распределённых по кластеру. Внутри партиции каждое сообщение имеет уникальный смещение (offset), определяющее его позицию в журнале.
Продюсеры и потребители
Продюсер (producer) — клиентское приложение, публикующее сообщения в топик. При отправке продюсер определяет целевую партицию: явно по ключу сообщения (хеширование ключа гарантирует упорядоченность для одинаковых ключей) или через стратегию балансировки (например, round-robin). Потребитель (consumer) — приложение, считывающее сообщения из партиций. Потребитель отслеживает своё текущее смещение для каждой партиции, что позволяет возобновлять чтение с последней прочитанной позиции после перезапуска.
Брокеры и кластеры
Брокер (broker) — отдельный узел Kafka, отвечающий за приём, хранение и доставку сообщений. Каждый брокер имеет уникальный идентификатор и управляет набором партиций (как лидеров, так и реплик). Кластер (cluster) — совокупность брокеров, работающих совместно под единым логическим пространством имён. Кластер обеспечивает отказоустойчивость через репликацию партиций и автоматическое перераспределение ролей при сбоях узлов.
Группы потребителей и балансировка нагрузки
Группа потребителей (consumer group) — логическая группа потребителей, совместно обрабатывающая сообщения из топика. Каждая партиция топика назначается ровно одному активному потребителю в группе. Это обеспечивает параллельную обработку: если топик содержит 12 партиций, максимум 12 потребителей в группе могут обрабатывать данные одновременно.
Балансировка нагрузки выполняется протоколом перебалансировки (rebalance protocol):
- Потребители регистрируются в группе через координатора группы (group coordinator) — специальный брокер, ответственный за управление состоянием группы.
- При изменении состава группы (добавление/удаление потребителя) запускается фаза перебалансировки.
- Выбирается лидер группы, который вычисляет план распределения партиций (partition assignment) с использованием стратегии (Range, RoundRobin, CooperativeSticky).
- План распространяется всем участникам; потребители останавливают обработку, применяют новое распределение и возобновляют чтение.
Стратегия CooperativeSticky (рекомендуемая в современных версиях) минимизирует перемещение партиций между потребителями при инкрементальных изменениях состава группы.
Внутреннее устройство кластера
Контроллер кластера
Контроллер (controller) — единственный брокер в кластере, ответственный за координацию метаданных:
- Назначение лидеров партиций при старте кластера или сбое узла
- Обработка запросов на создание/удаление топиков
- Управление ISR (In-Sync Replicas) — множеством реплик, синхронизированных с лидером
В режиме KRaft (Kafka Raft Metadata mode, начиная с версии 3.3) контроллер функционирует без зависимости от ZooKeeper, используя внутренний консенсусный протокол на основе Raft. Старые версии использовали внешний кворум ZooKeeper для хранения метаданных.
Механизм репликации
Каждая партиция имеет один лидер и набор реплик (обычно 2–3). Продюсеры пишут только в лидера; реплики асинхронно синхронизируются с лидером. Реплики, отставание которых не превышает порог replica.lag.time.max.ms, входят в множество ISR. Только реплики из ISR могут быть избраны новым лидером при сбое. Фактор репликации (replication factor) определяет общее количество копий данных для отказоустойчивости.
Физическое хранение данных
Данные партиции хранятся на диске в виде сегментированных файлов журнала:
- Основной файл
.logсодержит последовательность сообщений фиксированного размера (по умолчанию 1 ГБ) - Файл индекса
.indexотображает смещение в позицию в файле для быстрого поиска - Файл временного индекса
.timeindexпозволяет искать сообщения по метке времени - Файл
.txnindexиспользуется для поддержки транзакционных операций
Сообщения могут подвергаться сжатию на уровне партиции:
none— без сжатияgzip,snappy,lz4,zstd— алгоритмы сжатия с разным балансом скорости/степениcompact— режим очистки (compaction), сохраняющий только последнее значение для каждого ключа (актуально для топиков-хранилищ состояний)
Сегменты неизменяемы после закрытия; новые сообщения пишутся в активный сегмент. Устаревшие сегменты удаляются по политике хранения (время или объём).
Авторизация и управление доступом
Kafka поддерживает аутентификацию через механизмы SASL:
SASL/PLAIN— простая аутентификация логин/парольSASL/SCRAM— безопасная аутентификация с хранением хешей на сервереSASL/GSSAPI(Kerberos) — корпоративная аутентификацияSASL/OAUTHBEARER— токены OAuth 2.0
Управление доступом реализуется через ACL (Access Control Lists). Правила определяют разрешения для субъектов (пользователей, групп) на операции с ресурсами:
Пример правила:
Пользователь User:Alice имеет право на операцию READ для топика payments
Поддерживаются операции: READ, WRITE, CREATE, DELETE, ALTER, DESCRIBE, ALL. ACL применяются к ресурсам: топик, группа потребителей, кластер, транзакционный идентификатор.
Для межброкерного взаимодействия рекомендуется использовать отдельные учётные данные с минимальными необходимыми правами.
Программное управление через AdminClient
AdminClient предоставляет программный интерфейс для административных операций без использования CLI. Основные возможности:
Управление топиками
// Java: создание топика с 3 партициями и фактором репликации 2
NewTopic topic = new NewTopic("orders", 3, (short) 2);
CreateTopicsResult result = adminClient.createTopics(Collections.singleton(topic));
result.all().get();
Управление конфигурацией
# Python (confluent-kafka): изменение параметра топика
from confluent_kafka.admin import ConfigResource, ConfigSource
config_resource = ConfigResource(ConfigResource.Type.TOPIC, "orders")
config_resource.set_config("retention.ms", "604800000")
admin.alter_configs([config_resource])
Управление группами потребителей
// C# (Confluent.Kafka): получение информации о группе
var groups = admin.ListConsumerGroupsAsync().Result;
var description = admin.DescribeConsumerGroupsAsync(new[] { "order-processors" }).Result;
AdminClient поддерживает асинхронные операции, обработку ошибок через исключения и работу с метаданными кластера (список брокеров, топиков, партиций).
Утилиты командной строки для администрирования
Стандартный дистрибутив Kafka включает скрипты в каталоге bin/:
Управление топиками
# Создание топика
kafka-topics.sh --bootstrap-server broker1:9092 --create \
--topic events --partitions 6 --replication-factor 3
# Описание топика
kafka-topics.sh --bootstrap-server broker1:9092 --describe --topic events
# Удаление топика (требует включённого delete.topic.enable)
kafka-topics.sh --bootstrap-server broker1:9092 --delete --topic deprecated-topic
Работа с потребителями
# Просмотр групп потребителей
kafka-consumer-groups.sh --bootstrap-server broker1:9092 --list
# Описание состояния группы
kafka-consumer-groups.sh --bootstrap-server broker1:9092 \
--describe --group payment-processors
# Сброс смещений (требует остановки потребителей группы)
kafka-consumer-groups.sh --bootstrap-server broker1:9092 \
--group analytics --reset-offsets --to-earliest --execute --topic clicks
Диагностика кластера
# Проверка работоспособности брокера
kafka-broker-api-versions.sh --bootstrap-server broker1:9092
# Анализ распределения партиций
kafka-topics.sh --bootstrap-server broker1:9092 --describe \
--under-replicated-partitions
В режиме KRaft утилиты используют параметр --bootstrap-server; в режиме с ZooKeeper — --zookeeper.
Настройка и использование клиентских API
Producer API
Ключевые параметры конфигурации:
bootstrap.servers— начальный список брокеровacks— уровень подтверждения:0(без подтверждения),1(лидер),all(все реплики в ISR)retriesиretry.backoff.ms— политика повторных попытокcompression.type— алгоритм сжатия (none,gzip,snappy,lz4,zstd)batch.sizeиlinger.ms— параметры батчинга для повышения пропускной способности
Пример отправки с ключом для упорядоченности:
ProducerRecord<String, String> record =
new ProducerRecord<>("user-events", userId, eventJson);
producer.send(record, (metadata, exception) -> {
if (exception != null) handleFailure(exception);
});
Consumer API
Ключевые параметры:
group.id— идентификатор группы потребителейauto.offset.reset— поведение при отсутствии смещения (earliest,latest)enable.auto.commit— автоматическое подтверждение смещений (рекомендуетсяfalseдля контроля)max.poll.records— максимум записей за один вызовpoll()session.timeout.msиheartbeat.interval.ms— параметры жизненного цикла потребителя в группе
Рекомендуемый цикл обработки с ручным подтверждением:
while True:
records = consumer.poll(timeout_ms=1000)
for record in records:
process(record)
consumer.commit_sync() # Подтверждение после успешной обработки
Для обработки ошибок необходимо обрабатывать исключения CommitFailedException (возникает при перебалансировке во время коммита) и реализовывать стратегию повторных попыток для идемпотентной обработки сообщений.
Установка и настройка
Как настроить Kafka?
Установка Java
Kafka работает поверх Java, поэтому сначала нужно установить Java Development Kit (JDK).
Установка ZooKeeper
ZooKeeper — это координатор, который управляет кластером Kafka. В новых версиях Kafka (например, 3.x) ZooKeeper заменяется на Raft, но для старых версий он всё ещё обязателен.
- Скачайте и распакуйте ZooKeeper;
- Настройте конфигурацию. Создайте файл zoo.cfg в папке conf.
- Запустите ZooKeeper
Установка Kafka
- Скачайте и распакуйте Kafka.
- Настройте конфигурацию. Файл конфигурации находится в config/server.properties. Основные параметры:
broker.id=1
listeners=PLAINTEXT://localhost:9092
log.dirs=/tmp/kafka-logs
num.partitions=3
- Запустите Kafka:
bin/kafka-server-start.sh config/server.properties
- Чтобы Kafka запускался автоматически при загрузке системы, добавьте скрипт в автозагрузку или используйте systemd.
Создание топика.
Топик — это логический канал для передачи сообщений.
Создайте топик:
bin/kafka-topics.sh --create --topic my_topic --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1
Проверьте список топиков:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
Отправка и получение сообщений.
Пример отправки сообщения:
bin/kafka-console-producer.sh --topic my_topic --bootstrap-server localhost:9092
Пример получения сообщения:
bin/kafka-console-consumer.sh --topic my_topic --from-beginning --bootstrap-server localhost:9092
Подключение Kafka к программам.
В разных языках программирования испольхуются соответствующие библиотеки.
Java - библиотека org.apache.kafka:kafka-clients
Пример использования:
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
public class KafkaExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("my_topic", "key", "Hello, Kafka!"));
producer.close();
}
}
Python- библиотека kafka-python
Пример использования:
from kafka import KafkaProducer
producer = KafkaProducer(bootstrap_servers='localhost:9092')
producer.send('my_topic', value=b'Hello, Kafka!')
producer.flush()
JavaScript (Node.js)- библиотека kafkajs
Пример использования:
const { Kafka } = require('kafkajs');
const kafka = new Kafka({ brokers: ['localhost:9092'] });
const producer = kafka.producer();
await producer.connect();
await producer.send({
topic: 'my_topic',
messages: [{ value: 'Hello, Kafka!' }],
});
await producer.disconnect();
PHP - библиотека php-rdkafka
Пример использования:
<?php
$rk = new RdKafka\Producer();
$rk->addBrokers("localhost:9092");
$topic = $rk->newTopic("my_topic");
$topic->produce(RD_KAFKA_PARTITION_UA, 0, "Hello, Kafka!");
$rk->poll(0);
?>
Мониторинг
Мониторинг предоставляет инструмент для управления кластерами - Kafka Manager.
Пример установки:
docker run -it --rm -p 9000:9000 -e ZK_HOSTS="localhost:2181" sheepkiller/kafka-manager
Для визуализации можно использовать Grafana, а Prometheus для сбора метрик.