Big Data
Разработчику
Аналитику
Тестировщику
Архитектору
Инженеру
Big Data
Что такое Big Data?
Понятие Big Data, или большие данные, возникло как концептуальный ответ на качественный и количественный сдвиг в природе цифровой информации.
Большие данные представляют собой массивы информации, объёмы которых превышают возможности традиционных систем обработки. Такие данные характеризуются высокой скоростью поступления, разнообразием форматов и сложностью извлечения полезных сведений.
До конца XX века данные в информационных системах имели ограниченный объём, предсказуемую структуру и централизованное происхождение. Они генерировались преимущественно в рамках транзакционных систем, таких как бухгалтерские регистры, банковские операции или инвентарные базы. В этих условиях классические реляционные СУБД и методы аналитической обработки (OLAP) оказывались достаточными для хранения, обработки и извлечения значимой информации.
С развитием интернета, мобильных устройств, сенсорных сетей, социальных платформ и цифровых сервисов характер данных изменился кардинально. Появились потоки информации, которые отличались масштабом и скоростью поступления, разнородностью форматов и неопределённостью качества.
Именно в этом контексте и возникло понятие Big Data — совокупность условий, при которых традиционные методы управления данными становятся неэффективными или неприменимыми.
Big Data — это парадигма, в рамках которой переосмысливаются принципы сбора, хранения, обработки, анализа и интерпретации данных. Эта парадигма базируется на нескольких фундаментальных характеристиках, исторически получивших обозначение V-модель (от англ. V-attributes), и на новых архитектурных подходах к построению вычислительных систем.
Разберём пример. Система управления городским транспортом в мегаполисе с населением более десяти миллионов человек генерирует массивы больших данных. Каждый из десяти тысяч автобусов, трамваев и троллейбусов оснащён GPS-трекером, передающим координаты каждые пять секунд. Бесконтактные турникеты фиксируют посадку каждого пассажира с привязкой к маршруту и времени. Камеры видеофиксации отслеживают загруженность дорог и перекрёстков в реальном времени. Метеорологические датчики поставляют информацию о погодных условиях. Социальные сети и мобильные приложения предоставляют данные о планах перемещений пользователей. Ежедневный объём информации превышает петабайт.
Система хранения распределяет данные по географическим кластерам с репликацией между дата-центрами. Потоковая обработка анализирует текущую ситуацию на дорогах, прогнозирует заторы и корректирует расписание общественного транспорта. Исторические данные используются для моделирования транспортных потоков и планирования инфраструктуры. Машинное обучение выявляет закономерности поведения пассажиров и оптимизирует маршруты. Визуализация предоставляет диспетчерам единую панель управления с отображением всех транспортных средств, загруженности и прогнозов на ближайшие часы.
Как устроены большие данные?
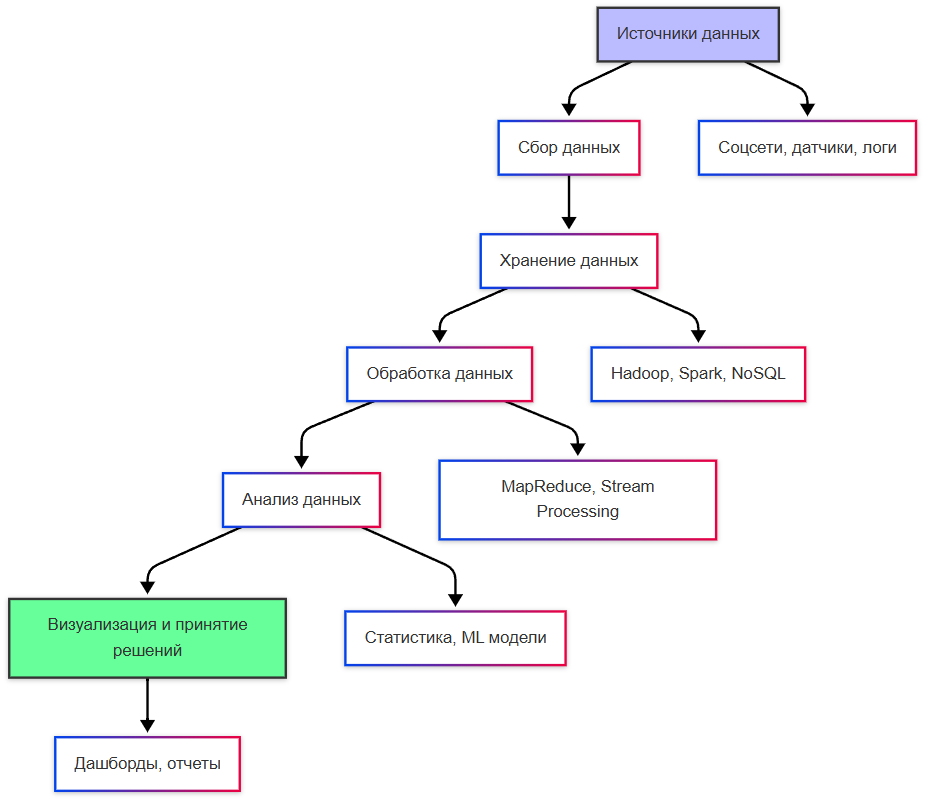
Экосистема больших данных состоит из нескольких взаимосвязанных слоёв:
- Источники генерируют потоки информации: веб-серверы, мобильные приложения, промышленные датчики, социальные сети.
- Системы сбора принимают эти потоки через API, очереди сообщений или прямые подключения.
- Хранилища распределяют данные по кластерам серверов с репликацией для отказоустойчивости; применяются распределённые файловые системы и колоночные базы данных.
- Вычислительные фреймворки выполняют параллельную обработку на сотнях узлов, используя принципы распределённых вычислений.
- Слой аналитики предоставляет инструменты для запросов, машинного обучения и визуализации.
- Управление данными включает каталоги метаданных, системы контроля качества и механизмы обеспечения безопасности.
Вся архитектура проектируется с учётом горизонтального масштабирования: добавление новых серверов увеличивает общую производительность системы.
Сбор информации
Сбор информации представляет собой процесс получения данных из различных источников для последующего использования. Этот процесс охватывает выявление источников, установление каналов передачи, извлечение сырых данных и их первичную подготовку. Сбор информации является первым этапом жизненного цикла данных и определяет качество всех последующих операций. Эффективный сбор обеспечивает полноту, своевременность и достоверность информации.
Современные системы сбора информации используют многоуровневую архитектуру:
- Источники данных подключаются через специализированные коннекторы: веб-скраперы для сайтов, API-клиенты для сервисов, агенты для сбора логов с серверов, драйверы для промышленного оборудования.
- Потоковые платформы принимают непрерывные потоки событий через брокеры сообщений, обеспечивающие буферизацию и отказоустойчивость.
- Пакетные системы извлекают данные периодическими заданиями по расписанию.
- Трансформационные модули выполняют нормализацию форматов, обогащение метаданными и базовую валидацию.
- Маршрутизаторы направляют подготовленные данные в соответствующие хранилища в зависимости от типа и назначения.
- Системы мониторинга отслеживают полноту сбора, задержки и ошибки подключения.
Конфигурация сбора управляется централизованно с возможностью динамического изменения параметров без остановки процессов.
Хранение информации
Хранение информации представляет собой организацию долговременного размещения данных с обеспечением доступности, целостности и безопасности. Этот процесс включает выбор носителей, проектирование структур размещения, управление жизненным циклом данных и обеспечение механизмов восстановления. Хранение информации служит основой для всех операций с данными: анализа, обработки, предоставления сервисов пользователям.
Первичные хранилища используют высокоскоростные SSD и оперативную память для горячих данных, к которым требуется мгновенный доступ.
Вторичные уровни применяют традиционные диски для данных средней активности. Архивные системы размещают холодные данные на энергоэффективных носителях с оптимизацией стоимости хранения.
Распределённые файловые системы разбивают файлы на блоки, реплицируют их по разным серверам и обеспечивают отказоустойчивость через алгоритмы консенсуса.
Объектные хранилища организуют данные как неизменяемые объекты с уникальными идентификаторами и метаданными.
Базы данных применяют разные модели: реляционные для структурированных транзакций, документные для гибких схем, колоночные для аналитических запросов.
Системы управления жизненным циклом автоматически перемещают данные между уровнями в зависимости от частоты обращений.
Механизмы репликации создают копии в географически распределённых центрах обработки данных.
Шифрование применяется как при передаче, так и при хранении.
Резервное копирование выполняется по расписанию с возможностью точечного восстановления на любой момент времени.
V-модель
Что такое V-модель?
V-модель представляет собой методологию жизненного цикла разработки программного обеспечения, визуализирующую взаимосвязь этапов проектирования и тестирования. Модель получила название по форме буквы V, где левая сторона отражает этапы декомпозиции требований и проектирования, а правая сторона — этапы интеграции и тестирования.
V-модель обеспечивает чёткое соответствие между каждым уровнем проектирования и соответствующим уровнем верификации. Эта модель подчёркивает важность планирования тестов на ранних стадиях разработки и гарантирует полноту проверки всех требований.
Структура V-модели состоит из двух симметричных ветвей:
- Левая нисходящая ветвь начинается с анализа бизнес-требований, затем формируются системные требования, создаётся архитектура системы, разрабатывается высокоуровневый дизайн компонентов и завершается детальным проектированием модулей. На каждом этапе левой ветви параллельно разрабатываются планы и сценарии тестирования для соответствующего уровня правой ветви.
- Правая восходящая ветвь начинается с модульного тестирования отдельных компонентов, затем выполняется интеграционное тестирование взаимодействия модулей, системное тестирование проверяет соответствие системных требований, завершается приёмочным тестированием на соответствие бизнес-требованиям. Каждый этап тестирования верифицирует результаты соответствующего этапа проектирования.
Документация создаётся на всех уровнях: спецификации требований, архитектурные описания, планы тестов, отчёты о результатах.
Модель предполагает строгую последовательность этапов с возможностью возврата только на предыдущий уровень при обнаружении дефектов. Отслеживаемость требований обеспечивается матрицами соответствия между пунктами требований и тестовыми сценариями.
Volume — объём
Объём является наиболее очевидной, но не единственной характеристикой Big Data. Если в 1990-е годы терабайт данных считался экстремальным объёмом, то сегодня организация может генерировать и обрабатывать экзабайты информации ежедневно. Например, социальные сети ежесекундно обрабатывают миллионы постов, изображений, видео и метаданных о поведении пользователей. Спутниковые системы дистанционного зондирования Земли производят петабайты данных в день.
Big Data — это относительное состояние, при котором объём данных превышает возможности традиционных систем хранения и обработки с точки зрения производительности, стоимости или масштабируемости.
Velocity — скорость
Скорость поступления и обработки данных — ключевой аспект Big Data. В отличие от пакетной обработки (batch processing), где данные собираются, а затем анализируются с задержкой, в условиях Big Data часто требуется обработка в реальном времени (stream processing). Примеры: фрод-детекция в банковских транзакциях, мониторинг сетевого трафика, управление автономными транспортными средствами.
Velocity определяет частоту поступления событий и требования к времени реакции системы: от микросекунд в высокочастотном трейдинге до минут в системах мониторинга инфраструктуры.
Variety — разнородность
Традиционные СУБД работают с структурированными данными: таблицами с предопределённой схемой. Big Data, напротив, включает полуструктурированные (JSON, XML, логи) и неструктурированные (аудио, видео, текстовые документы, изображения) форматы. Системы Big Data должны обеспечивать гибкость в обработке этих форматов без предварительной нормализации или строгой типизации.
Эта характеристика породила развитие технологий NoSQL, таких как документные базы (MongoDB), колоночные хранилища (Cassandra, HBase), графовые базы (Neo4j) и ключ-значение хранилища (Redis, DynamoDB).
Veracity — достоверность
Veracity отражает степень доверия к данным. В условиях Big Data данные могут быть шумными, неполными, противоречивыми или содержать ошибки. Пример: показания датчиков IoT могут быть искажены внешними помехами; пользовательские отзывы в соцсетях могут быть сгенерированы ботами; данные из открытых источников могут быть устаревшими.
Учёт veracity требует внедрения методов очистки данных (data cleansing), валидации, фузии источников и оценки неопределённости. Без учёта этого атрибута выводы, сделанные на основе Big Data, могут оказаться ошибочными, несмотря на высокую статистическую значимость.
Value — ценность
Ценность возникает только в результате осмысленной интерпретации и практического применения. Например, данные о геолокации мобильных устройств могут быть использованы для оптимизации городского транспорта, но без правильной модели анализа они останутся лишь массивом координат и временных меток.
Value подчёркивает необходимость тесной интеграции технологий Big Data с предметной областью: бизнес-аналитикой, медициной, логистикой, наукой. Это также акцентирует роль научной строгости в построении моделей машинного обучения и статистического вывода.
Примечание: В литературе иногда упоминаются дополнительные V-характеристики — например, Variability (вариативность — изменение форматов и семантики во времени), Visualization (визуализация как средство интерпретации), Volatility (временная устойчивость данных). Однако ядром остаются первые пять, так как они охватывают основные вызовы, с которыми сталкиваются системы Big Data.
Архитектурные основы
Концепции
Классическое клиент-серверное взаимодействие и централизованные СУБД не масштабируются линейно. Проблема заключается в ёмкости дисковой памяти и в вычислительной сложности операций, задержках ввода-вывода и сетевых узких местах. Решение заключается в переходе к горизонтальному масштабированию (scale-out) — добавлению узлов в кластер вместо увеличения мощности отдельного сервера.
Ключевой концепцией, позволившей реализовать масштабируемость Big Data, стал MapReduce — программная модель, предложенная Google в 2004 году. Она разделяет задачу обработки на две фазы:
- Map: параллельная трансформация входных данных в пары «ключ-значение».
- Reduce: агрегация значений по ключам.
Эта модель лежит в основе Apache Hadoop — экосистемы, включающей распределённую файловую систему (HDFS) и движок выполнения заданий (YARN). Hadoop позволил обрабатывать петабайты данных на недорогом commodity-оборудовании, что стало прорывом в демократизации аналитики.
Однако MapReduce оказался неэффективен для итеративных алгоритмов (например, машинного обучения) и интерактивных запросов. Это привело к появлению Apache Spark — фреймворка, в котором данные могут храниться в памяти между операциями, что даёт ускорение до 100 раз по сравнению с дисковыми операциями Hadoop.
Современная архитектура Big Data — это многоуровневый конвейер (data pipeline), включающий:
- Источники данных (sensors, logs, APIs, databases, streams).
- Системы инжеста (Apache Kafka, Apache NiFi, AWS Kinesis) — для буферизации и маршрутизации потоков.
- Хранилища:
- «Озеро данных» (data lake) — необработанные, неструктурированные данные.
- «Хранилище данных» (data warehouse) — очищенные, структурированные данные для анализа.
- Средства обработки (Spark, Flink, Beam) — как пакетные, так и потоковые.
- Слой аналитики и визуализации (BI-инструменты, ML-модели, дашборды).
Такой подход позволяет гибко адаптироваться под требования различных сценариев: предиктивная аналитика, реальное время, историческое моделирование.
Интернет вещей
Интернет вещей (Internet of Things, IoT) представляет собой сеть физических устройств, оснащённых датчиками, программным обеспечением и возможностью подключения к интернету для обмена данными. Эти устройства взаимодействуют друг с другом и с центральными системами без прямого участия человека.
Интернет вещей расширяет концепцию сетевого взаимодействия за пределы традиционных компьютеров и смартфонов на повседневные объекты: бытовую технику, транспортные средства, промышленное оборудование, городскую инфраструктуру. Основная ценность интернета вещей заключается в автоматизации процессов, повышении эффективности ресурсов и создании новых сервисов на основе данных от устройств.
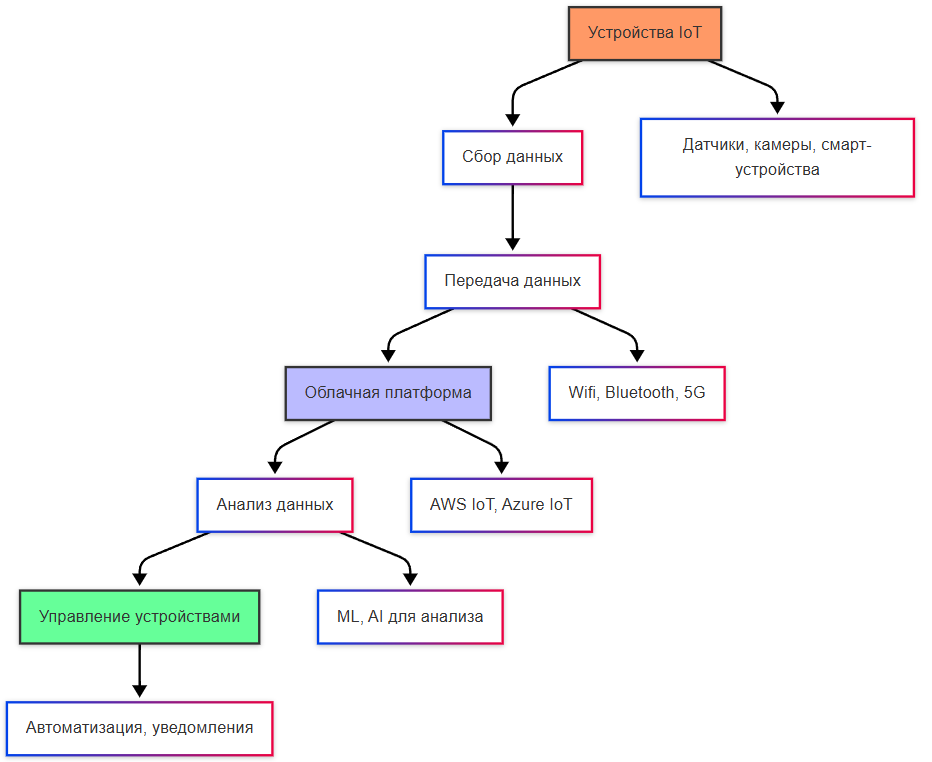
Характеристики данных от IoT-устройств соответствуют всем пяти V-атрибутам Big Data в крайней степени:
- Volume: миллионы устройств, каждое из которых может отправлять данные каждые несколько миллисекунд.
- Velocity: требуется обработка в реальном времени для детекции аномалий или управления процессами.
- Variety: данные могут поступать в бинарных протоколах (MQTT, CoAP), сериализованных форматах (Protobuf, Avro) или через REST-интерфейсы.
- Veracity: датчики подвержены шуму, сбоям, дрейфу калибровки.
- Value: ценность заключается в извлечении паттернов поведения, предиктивном обслуживании (predictive maintenance), оптимизации ресурсов.
Важно отметить, что архитектура IoT-систем предполагает иерархию обработки: от edge-вычислений (фильтрация и агрегация на устройстве или шлюзе) до cloud-аналитики (глобальное моделирование). Такой подход снижает нагрузку на сеть и обеспечивает устойчивость при временной потере соединения.
Архитектура интернета вещей состоит из четырёх взаимосвязанных слоёв:
- Устройства и датчики формируют периферийный слой: сенсоры измеряют физические параметры, исполнительные механизмы воздействуют на окружающую среду, микроконтроллеры выполняют локальную обработку.
- Сетевой слой обеспечивает передачу данных через различные протоколы: сотовые сети для мобильных устройств, Wi-Fi и Ethernet для стационарных объектов, LPWAN для энергоэффективных сенсоров с низкой пропускной способностью, специализированные промышленные протоколы.
- Платформенный слой предоставляет сервисы управления устройствами: регистрацию, аутентификацию, обновление прошивок, мониторинг состояния, маршрутизацию сообщений.
- Аналитический слой обрабатывает потоки данных: фильтрацию, агрегацию, применение алгоритмов машинного обучения для выявления аномалий и прогнозирования.
Порой формируется и прикладной слой, как пятая часть. Он реализует бизнес-логику и пользовательские интерфейсы: панели управления, уведомления, автоматизированные сценарии.
Безопасность пронизывает все слои: шифрование каналов связи, управление ключами, контроль доступа, изоляция критических систем.
Энергоснабжение устройств решается через сетевые подключения, аккумуляторы с низким энергопотреблением или технологии сбора энергии из окружающей среды.
Умный сельскохозяйственный комплекс площадью пять тысяч гектаров демонстрирует применение интернета вещей в аграрном секторе. Почвенные датчики, размещённые в шахматном порядке с шагом пятьдесят метров, измеряют влажность, температуру, кислотность и содержание питательных веществ каждые пятнадцать минут. Метеостанции на территории поля отслеживают осадки, влажность воздуха, скорость ветра и солнечную радиацию. Дроны с мультиспектральными камерами выполняют еженедельные облёты для оценки состояния посевов. Автоматизированные системы полива получают команды от центрального контроллера и включают секции капельного орошения с точностью до отдельных грядок. Удобрительные комплексы дозируют внесение питательных веществ на основе данных с датчиков. Все устройства подключены через сеть LoRaWAN с радиусом действия до пятнадцати километров, обеспечивающую связь в условиях отсутствия сотового покрытия. Шлюзы концентрируют данные и передают их в облачную платформу через спутниковый канал. Платформа коррелирует показания датчиков с прогнозами погоды и историческими урожайными данными. Алгоритмы машинного обучения формируют карты внесения воды и удобрений с пространственным разрешением до одного квадратного метра. Тракторы с автопилотом следуют этим картам, обеспечивая точное земледелие. Фермер получает мобильные уведомления о критических отклонениях и ежедневные отчёты об оптимальных действиях для каждого участка поля. Система снижает расход воды на тридцать процентов и повышает урожайность на двадцать процентов по сравнению с традиционными методами.
Цикл работы с большими данными
Обработка Big Data не сводится к запуску аналитических скриптов. Это строго регламентированный жизненный цикл данных, включающий следующие этапы:
Сбор (Data Ingestion)
Сбор данных — это не просто копирование файлов. Это управляемый процесс инжеста, в котором решаются вопросы:
- Синхронизации источников: как обеспечить целостность при частичном сбое?
- Сериализации: выбор формата (JSON, Parquet, ORC), баланс между читаемостью и компактностью.
- Буферизации: использование очередей сообщений (Kafka, RabbitMQ) для декуплирования производителей и потребителей данных.
Особое внимание уделяется idempotency — свойству операции, при котором повторный вызов не изменяет результат. Это критично в распределённых системах с возможными повторными отправками сообщений.
Хранение
Существует принципиальное различие между data lake и data warehouse:
- Data lake — централизованное хранилище «сырых» данных в их исходной форме. Поддерживает любые форматы. Основная цель — сохранение информации без предварительного отбора.
- Data warehouse — структурированное, оптимизированное под аналитические запросы (OLAP) хранилище. Данные проходят ETL (Extract, Transform, Load) или ELT (Extract, Load, Transform).
Современные платформы, такие как Delta Lake или Apache Iceberg, стремятся устранить этот разрыв, обеспечивая ACID-свойства, версионирование и поддержку потоковой инжестии поверх файловых систем (например, Amazon S3 или HDFS).
Обработка
Обработка делится на две парадигмы:
- Batch processing — обработка больших объёмов данных с задержкой. Подходит для исторического анализа, генерации отчётов, обучения моделей. Реализуется через Hadoop MapReduce, Apache Spark, Apache Flink (в batch-режиме).
- Stream processing — обработка непрерывных потоков с минимальной задержкой. Используется в системах мониторинга, фрод-детекции, телеметрии. Реализуется через Apache Kafka Streams, Apache Flink, Spark Streaming, Google Cloud Dataflow.
Выбор парадигмы определяется бизнес-требованиями к latency (времени от события до реакции) и throughput (количеству событий в секунду).
Анализ и сводка
На этом этапе данные превращаются в знания. Анализ может быть:
- Описательным (что произошло? — дашборды, отчёты),
- Диагностическим (почему произошло? — корреляционный анализ),
- Предиктивным (что произойдёт? — машинное обучение),
- Прескриптивным (что делать? — оптимизация решений).
Сводка (aggregation) — ключевой метод уменьшения объёма: суммирование, усреднение, группировка по измерениям. Однако при работе с Big Data важно учитывать статистическую репрезентативность: агрегированные метрики могут скрывать важные выбросы или субпопуляции.
Распределённые системы обработки данных
Apache Hadoop
Hadoop — это экосистема, включающая:
- HDFS (Hadoop Distributed File System) — отказоустойчивая файловая система, разделяющая файлы на блоки (по умолчанию 128 МБ), реплицируемые по узлам кластера.
- MapReduce — модель программирования, реализующая принцип «вычисления перемещаются к данным», что минимизирует сетевой трафик.
- YARN (Yet Another Resource Negotiator) — менеджер ресурсов, позволяющий запускать MapReduce и другие фреймворки (Spark, Flink) на одном кластере.
Hadoop оказался революционным, но его недостатки — высокая задержка, зависимость от дисковой I/O, сложность написания логики — ограничили применение в интерактивных сценариях.
Apache Spark
Spark устраняет ключевые ограничения Hadoop за счёт:
- In-memory вычислений: промежуточные данные хранятся в оперативной памяти, что ускоряет итеративные алгоритмы (например, k-means, градиентный спуск).
- Единой модели выполнения: один движок поддерживает batch, streaming, SQL, machine learning (MLlib) и графовые вычисления (GraphX).
- Высокоуровневых API на Scala, Java, Python и R, что снижает порог входа.
Spark дополняет Hadoop: он может использовать HDFS как хранилище, но не требует MapReduce. Современные архитектуры часто комбинируют обе технологии в зависимости от задачи.
Роль SQL и NoSQL в экосистеме Big Data
SQL в Big Data
Несмотря на доминирование NoSQL в ранних решениях Big Data, SQL сохраняет своё значение как стандарт декларативного запроса. Современные движки предоставляют SQL-интерфейсы поверх распределённых данных:
- Apache Hive — позволяет выполнять SQL-подобные запросы (HiveQL) над HDFS через MapReduce или Tez.
- Apache Spark SQL — интегрирован в Spark, поддерживает оптимизацию запросов через Catalyst и генерацию кода.
- Presto/Trino, Apache Druid, ClickHouse — аналитические СУБД, оптимизированные для быстрых агрегаций по большим объёмам.
SQL здесь выступает как инструмент бизнес-аналитики, позволяющий аналитикам работать с Big Data без глубокого знания распределённых вычислений.
NoSQL в Big Data
NoSQL-системы возникли как реакция на ограничения реляционной модели в условиях масштабируемости и гибкости схемы. В Big Data они выполняют следующие роли:
- Хранение неструктурированных данных: документные базы (MongoDB) — для JSON-объектов.
- Высокая пропускная способность записи: колоночные базы (Cassandra, ScyllaDB) — для временных рядов, логов.
- Сложные связи: графовые базы (Neo4j, Amazon Neptune) — для анализа социальных сетей, рекомендаций.
- Кэширование и быстрый доступ: ключ-значение хранилища (Redis, DynamoDB).
NoSQL — это альтернативная модель данных, оптимизированная под конкретные паттерны доступа. Выбор между SQL и NoSQL определяется семантикой задачи.
Машинное обучение и искусственный интеллект в Big Data
Big Data и машинное обучение (ML) находятся в симбиотическом отношении: большие объёмы данных питают сложные модели, а модели извлекают из данных скрытые закономерности.
Обучение на распределённых данных
Классические ML-библиотеки (scikit-learn) работают в памяти одного узла. В Big Data требуется распределённое обучение:
- Apache Spark MLlib — реализует алгоритмы (линейная регрессия, случайный лес, k-means) с распределённой обработкой данных.
- Horovod, TensorFlow Distributed, PyTorch DDP — фреймворки для параллельного обучения нейросетей на GPU-кластерах.
- Federated Learning — парадигма, при которой модель обучается локально на устройствах (например, смартфонах), а обмениваются только градиенты, что защищает приватность.
Проблемы качества и интерпретируемости
Работа с Big Data усиливает риски:
- Переобучение: при большом числе признаков модель может «запомнить» шум.
- Смещение данных (bias): если данные собраны из несбалансированных источников (например, только из одного региона), модель будет ошибаться на других популяциях.
- Отсутствие интерпретируемости: глубокие нейросети часто работают как «чёрный ящик», что недопустимо в медицине, финансах, праве.
Поэтому в промышленных системах Big Data всё чаще применяются методы объяснимого ИИ (XAI): SHAP, LIME, feature importance, а также мониторинг дрейфа данных (data drift) в production.